Linux Note
C 语言之解析局部变量返回
一般的来说,函数是可以返回局部变量的。 局部变量的作用域只在函数内部,在函数返回后,局部变量的内存已经释放了。因此,如果函数返回的是局部变量的值,不涉及地址,程序不会出错。但是如果返回的是局部变量的地址(指针)的话,程序运行后会出错。因为函数只是把指针复制后返回了,但是指针指向的内容已经被释放了,这样指针指向的内容就是不可预料的内容,调用就会出错。
准确的来说,函数不能通过返回指向栈内存的指针(注意这里指的是栈,返回指向堆内存的指针是可以的)。
1. Linux 基础命令
stat命令用于显示文件的状态信息。stat命令的输出信息比 ls 命令的输出信息要更详细。
1.0 创建用户
创建用户命令两条:
adduser
useradd
用户删除命令:
- userdel
两个用户创建命令之间的区别:
adduser: 会自动为创建的用户指定主目录、系统shell版本,会在创建时输入用户密码。
useradd:需要使用参数选项指定上述基本设置,如果不使用任何参数,则创建的用户无密码、无主目录、没有指定shell版本。
1 | 使用 adduser |
因此 adduser 常用参数选项为:
--home: 指定创建主目录的路径,默认是在/home目录下创建用户名同名的目录,这里可以指定;如果主目录同名目录存在,则不再创建,仅在登录时进入主目录。--quiet: 即只打印警告和错误信息,忽略其他信息。--debug: 定位错误信息。--conf: 在创建用户时使用指定的configuration文件。--force-badname: 默认在创建用户时会进行/etc/adduser.conf中的正则表达式检查用户名是否合法,如果想使用弱检查,则使用这个选项,如果不想检查,可以将/etc/adduser.conf中相关选项屏蔽。
1 | 使用 useradd |
为用户指定参数的 useradd 命令,常用命令行选项:
-d: 指定用户的主目录-m: 如果存在不再创建,但是此目录并不属于新创建用户;如果主目录不存在,则强制创建; -m和-d一块使用。-s: 指定用户登录时的shell版本-M: 不创建主目录
1 | 解释: |
删除用户命令
userdel
只删除用户:
sudo userdel 用户名
连同用户主目录一块删除:
sudo userdel -r 用户名
相关文件:
- /etc/passwd - 使 用 者 帐 号 资 讯,可以查看用户信息
- /etc/shadow - 使 用 者 帐 号 资 讯 加 密
- /etc/group - 群 组 资 讯
- /etc/default/useradd - 定 义 资 讯
- /etc/login.defs - 系 统 广 义 设 定
- /etc/skel - 内 含 定 义 档 的 目 录
为组用户增加 root 权限:
1 | 修改 /etc/sudoers 文件,找到下面一行,在 root 下面添加一行,如下所示: |
1.1 ln 软硬链接
硬链接
硬链接说白了是一个指针,指向文件索引节点,系统并不为它重新分配inode。可以用: ln 命令来建立硬链接。
尽管硬链接节省空间,也是Linux系统整合文件系统的传统方式,但是存在一下不足之处:
(1)不可以在不同文件系统的文件间建立链接
(2)只有超级用户才可以为目录创建硬链接。
软链接(符号链接)
软链接克服了硬链接的不足,没有任何文件系统的限制,任何用户可以创建指向目录的符号链接。因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接。
建立软链接,只要在 ln 后面加上选项 –s
1 | ln -s abc cde # 建立 abc 的软连接 |
删除链接
1 | rm -rf symbolic_name |
1.2 find grep xargs
1 | 列出当前目录及子目录下所有文件和文件夹 |
1 | grep 内容过滤 |
1 | xargs |
1.3 VIM
设置 ~/.bashrc
添加 set -o vi – 可以直接使用 vim 的各种快捷键
VIM 快捷键:
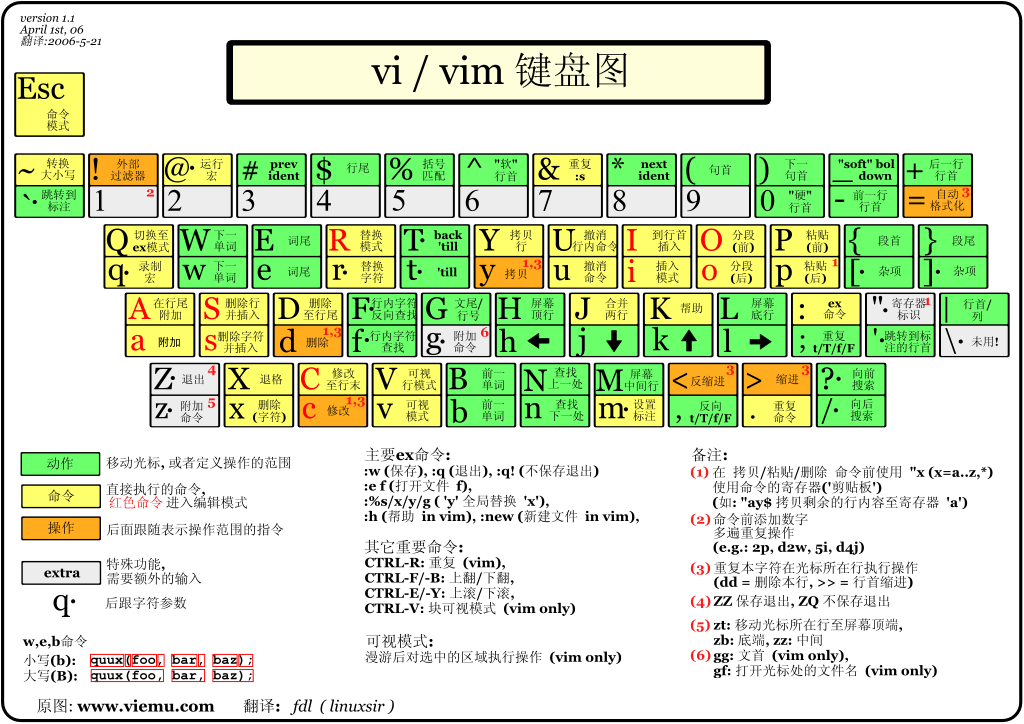
1.4 GCC
gcc 工作流程
1 | 预处理 头文件展开 宏替换 |
gcc 参数
1 | 指定编译输出的名字 |
1.5 库文件制作
静态库制作和使用
1 | 步骤 |
动态库制作和使用
1 | 步骤 |
1.6 Makefile
makefile 的三要素:
- 目标
- 依赖
- 规则命令
写法:
- 目标:依赖
- tab键 规则命令
1 | app: main.c add.c sub.c div.c mul.c |
如果更改其中一个文件,所有的源码都重新编译
可以考虑编译过程分解,先生成 .o 文件,然后使用 .o 文件编程结果
规则是递归的,依赖文件如果比目标文件新,则重新生成目标文件
1 | ObjFiles=main.o add.o sub.o div.o mul.o |
makefile 的隐含规则:默认处理第一个目标
1 | get all .c files |
makefile 变量:
- $@ 代表目标
- $^ 代表全部依赖
- $< 第一个依赖
- $? 第一个变化的依赖
1 | get all .c files |
make -f makefile1 指定makefile文件进行编译
1 | SrcFiles=$(wildcard *.c) |
1.7 gdb 调试
gdb 调试入门,大牛写的高质量指南
gdb 调试利器
启动gdb:gdb app
在gdb启动程序:
- r(un) – 启动 可以带参数启动
- start – 启动 - 停留在main函数,分步调试
- n(ent) – 下一条指令
- s(tep) – 下一条指令,可以进入函数内部,库函数不能进
- q(uit) – 退出 gdb
- b(reak) num – 指定行号,函数, 文件:行号 设置断点
- b 行号 – 主函数所在文件的行
- b 函数名
- b 文件名:行号
- l(ist) 文件:行号 – 查看代码
- l – 显示主函数对应的文件
- l 文件名:行号
- info b – 查看断点信息
- d(el) num – 删除断点
- c – continue 跳到下一个断点
- p(rint) – 打印参数,或者变量值
- ptype 变量 – 查看变量类型
- set – 设置变量的值
- set argc=4
- set argv[1]=“12”
- set argv[2] = “7”
- display argc – 跟踪显示参数或者变量的变化
- info display
- undisplay num
- b num if xx == xx – 条件断点
gdb跟踪core
设置生成 core :ulimit -c unlimited
取消生成 core: ulimit -c 0
设置 core 文件格式:/proc/sys/kernel/core_pattern
文件不能 vi,可以用后面的套路:echo “/corefile/core-%e-%p-%t” > core_pattern
core 文件如何使用:
gdb app core
如果看不到在哪儿core 可以用 where 查看在哪儿产生的 core
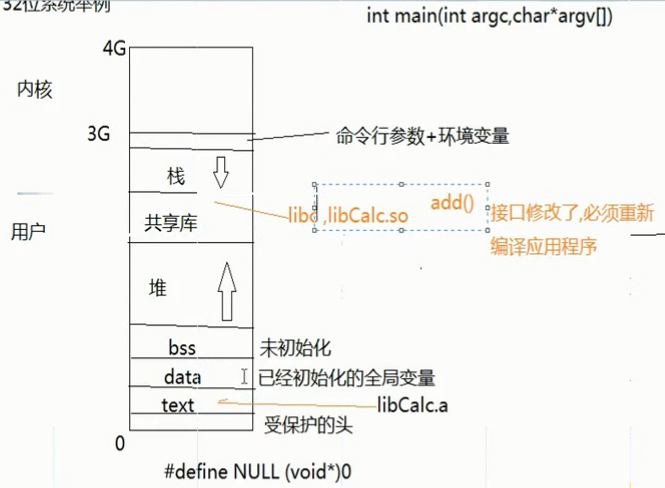
2. 系统api与库函数的关系

3. Linux 系统编程
ulimit -a 查看所有资源的上限
env 查看环境变量
echo $PATH 打印指定的环境变量
char *getenv() 获取环境变量
创建一个进程:
pid_t fork(void)
返回值:
- 失败 -1
- 成功,返回两次
- 父进程返回子进程的 id
- 子进程返回 0
获得pid,进程 id,获得当前进程
pid_t getpid(void)
获得当前进程父进程的 id
pid_t getppid(void)
ps ajx 查看父进程和子进程相关信息
进程共享:
父子进程之间在fork后,有哪些相同和不同:
- 父子相同处:
- 全局变量
- data、text、栈、堆、环境变量
- 用户 ID
- 宿主目录、进程工作目录、信号处理方式…
- 父子不同处:
- 进程 ID
- 父进程 ID
- 进程运行时间
- 闹钟(定时器)
- 未决信号集
似乎,子进程复制了父进程 0-3G 用户空间内容,以及父进程的 PCB, 但 pid 不同。真的每 fork 一个子进程都要将父进程的 0-3G 地址空间完全拷贝一份,然后在映射至屋里内存吗?当然不是,父子进程间遵循读时共享写时复制。这样设计,无论子进程执行父进程的逻辑还是执行自己的逻辑都能节省内存开销。
孤儿进程与僵尸进程:
- 孤儿进程
- 父进程死了,子进程被 init 进程领养
- 僵尸进程
- 子进程死了,父进程没有回收子进程的资源(PCB)
回收子进程,知道子进程的死亡原因,作用:
- 阻塞等待
- 回收子进程资源
- 查看死亡原因
pid_t wait(int *status)
- status 传出参数
- 返回值
- 成功返回终止的子进程 ID
- 失败 返回 -1
子进程的死亡原因:
- 正常死亡 WIFEXITED
- 如果 WIFEXITED 为真,使用 WEXITSTATUS 得到退出的状态
- 非正常死亡 WIFSIGNALED
- 如果 WIFSIGNALED 为真,使用 WTERMSIG 得到信号
pid_t waitpid(pid_t pid, int *status, int options)
- pid
< -1组ID-1回收任意0回收和调用进程组 ID 相同组内的子进程>0回收指定的 pid
- option
- 0 与 wait 相同,也会阻塞
- WNOHANG 如果当前没有子进程退出,会立刻返回
- 返回值
- 如果设置了 WNOHANG ,那么如果没有子进程退出,返回 0
- 如果有子进程退出返回退出的 pid
- 失败返回 -1 (没有子进程)
- 如果设置了 WNOHANG ,那么如果没有子进程退出,返回 0
3.1 IPC 概念
IPC : 进程间通信,通过内核提供的缓存区进行数据交换的机制
IPC 通信的方式有几种:
- pipe 管道 – 最简单
- fifo 有名管道
- mmap 文件映射共享IO – 速度最快
- 本地 socket 最稳定
- 信号 携带信息量最小
- 共享内存
- 消息队列
读管道:
- 写端全部关闭 – read 读到 0, 想当于读到文件末尾
- 写端没有全部关闭
- 有数据 – read 读到数据
- 没有数据 – read 阻塞 fcntl 函数可以更改非阻塞
写管道:
- 读端全部关闭 – ? 产生一个信号 SIGPIPE,程序异常终止
- 读端未全部关闭
- 管道已满 – write 阻塞 – 如果要显示现象,读端一直不读,写端狂写。
- 管道未满 – write 正常写入
管道缓冲区大小
可以使用 ulimit –a 命令来查看当前系统中创建管道文件所对应的内核缓冲区大小。通常为:
1 | pipe size (512 bytes, -p) 8 |
也可以使用 fpathconf 函数,借助参数选项来查看。使用该宏应引入头文件<unistd.h>
long fpathconf(int fd, int name);
- 成功:返回管道的大小
- 失败:-1,设置errno
管道的优劣
优点:
- 简单,相比信号,套接字实现进程间通信,简单很多。
缺点:
- 只能单向通信,双向通信需建立两个管道。
- 只能用于父子、兄弟进程(有共同祖先)间通信。该问题后来使用fifo有名管道解决。
FIFO通信
FIFO 有名管道,实现无血缘关系进程通信
- 创建一个管道的伪文件
- mkfifo myfifo 命令创建
- 也可以使用函数
int mkfifo(const char *pathname, mode_t mode);
- 内核会针对 fifo 文件开辟一个缓存区,操作 fifo 文件,可以操作缓存区,实现进程间通信 – 实际上就是文件读写
mmap映射共享区
1 | void *mmap(void *adrr, size_t length, int prot, int flags, int fd, off_t offset); |
返回:
- 成功:返回创建的映射区首地址;
- 失败:MAP_FAILED宏
参数:
- addr: 建立映射区的首地址,由Linux内核指定。使用时,直接传递NULL
- length: 欲创建映射区的大小
- prot: 映射区权限 PROT_READ、PROT_WRITE、PROT_READ|PROT_WRITE
- flags: 标志位参数(常用于设定更新物理区域、设置共享、创建匿名映射区)
- MAP_SHARED: 会将映射区所做的操作反映到物理设备(磁盘)上。(共享的)
- MAP_PRIVATE: 映射区所做的修改不会反映到物理设备。(私有的)
- fd: 用来建立映射区的文件描述符
- offset: 映射文件的偏移(4k的整数倍)
释放映射区
1 | int munmap(void *addr, size_t length); |
匿名映射
通过使用我们发现,使用映射区来完成文件读写操作十分方便,父子进程间通信也较容易。但缺陷是,每次创建映射区一定要依赖一个文件才能实现。通常为了建立映射区要open一个temp文件,创建好了再unlink、close掉,比较麻烦。 可以直接使用匿名映射来代替。其实Linux系统给我们提供了创建匿名映射区的方法,无需依赖一个文件即可创建映射区。同样需要借助标志位参数flags来指定。
使用 MAP_ANONYMOUS(或 MAP_ANON ), 如:
1 | int *p = mmap(NULL, 4, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0); |
需注意的是,MAP_ANONYMOUS和MAP_ANON这两个宏是Linux操作系统特有的宏。在类Unix系统中如无该宏定义,可使用如下两步来完成匿名映射区的建立。
1 | /* |
信号的概念
信号的特点
- 简单,不能带大量信息,满足特定条件发生
信号的机制
- 进程 B 发送给进程 A ,内核产生信号,内核处理
信号的产生
- 按键产生
- 函数调用 kill、raise、abort
- 定时器 alarm、setitimer
- 命令产生 kill
- 硬件异常、段错误、浮点型错误、总线错误、SIGPIPE
信号的状态
- 产生
- 递达 信号到达并且处理完
- 未决 信号被阻塞
信号的默认处理方式
- 忽略
- 执行默认动作
- 捕捉
信号的 4 要素
- 编号
- 事件
- 名称
- 默认处理动作
- 忽略
- 终止
- 终止 + core
- 暂停
- 继续
3.2 进程和线程
- 进程组
- 会话
- 守护进程
创建一个会话需要注意以下 5 点注意事项:
- 调用进程不能是进程组组长,该进程编程新会话首进程(session header)
- 该进程成为一个新进程组的组长进程
- 新会话丢弃原有的控制终端,该会话没有控制终端
- 该调用进程是组长进程,则出错返回
- 建立会话时,先调用fork,父进程终止,子进程调用 setsid
守护进程:
Daemon 进程,是 Linux 中的后台服务进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。一般采用以 d 结尾的名字。
创建守护进程,最关键的一步是调用 setsid 函数创建一个新的 session 。并成为 session leader。
创建守护进程模型:
- 创建子进程,父进程退出
- 所有工作在子进程中进行形式上脱离了控制终端
- 在子进程中创建新会话
- setsid() 函数
- 使子进程完全能独立出来,脱离控制
- 改变当前目录为根目录
- chdir() 函数
- 防止占用可卸载的文件系统
- 也可以换成其他路径
- 重设文件权限掩码
- umask() 函数
- 防止继承的文件创建屏蔽字拒绝某些权限
- 增加守护进程灵活性
- 关闭文件描述符
- 继承的打开文件不会用到,浪费系统资源,无法卸载
- 开始执行守护进程核心工作
- 守护进程退出处理程序模型
会话:进程组的更高一级,多个进程组对应一个会话
进程组:多个进程在同一个组,第一个进程默认是进程组的组长
创建会话的时候,组长不可以创建,必须是组员创建。
创建会话的步骤:创建子进程,父进程终止,子进程当会长
守护进程的步骤:
- 创建子进程 fork
- 父进程退出
- 子进程当会长 setsid
- 切换工作目录 $HOME
- 设置掩码 umask
- 关闭文件描述符,为了避免浪费资源
- 执行核心逻辑
- 退出
1 | int pthread_create(pthread_t *thread, const pthread_attr_t *attr, |
1 |
|
扩展了解:
通过 nohup 指令也可以达到守护进程创建的效果
nohup cmd [> 1.log] &
- nohup 指令会让 cmd 收不到 SIGHUP 信号
- & 代表后台运行
线程是最小的执行单位,进程是最小的系统资源分配单位
查看 LWP 号:ps -Lf pid 查看指定线程的 lwp 号
线程非共享资源
- 线程 ID
- 处理器现场和栈指针(内核栈)
- 独立的栈空间(用户空间栈)
- errno 变量
- 信号屏蔽字
- 调度优先级
线程优缺点:
- 优点:
- 提高程序并发性
- 开销小
- 数据通信、共享数据方便
- 缺点:
- 库函数 不稳定
- 调试、编写困难
- 对信号支持不好
1 | alias echomake=`cat ~/bin/makefile.template >> makefile` |
线程退出注意事项:
- 在线程中使用pthread_exit
- 在线程中使用 return (主控线程return 代表退出进程)
- exit 代表退出整个进程
线程回收函数:
1 | int pthread_join(pthread_t thread, void **retval); |
杀死线程:
1 | int pthread_cancel(pthread_t thread); |
被pthread_cancel 杀死的线程,退出状态为 PTHREAD_CANCELED
线程分离:
1 | int pthread_detach(pthread_t thread); |
此时不需要 pthread_join回收资源
线程 ID 在进程内部是唯一的
进程属性控制:
初始化线程属性
1
int pthread_attr_init(pthread_attr_t *attr);
销毁线程属性
1
int pthread_attr_destroy(pthread_attr_t *attr);
设置属性分离态
1
2
3
4
5
6
7int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
# - PTHREAD_CREATE_DETACHED 线程分离
# - PTHREAD_CREATE_JOINABLE 允许回收
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
查看线程库版本:
1 | getconf GNU_LIBPTHREAD_VERSION |
创建多少个线程?
- cpu核数 * 2 + 2
线程同步:
- 协调步骤,顺序执行
解决同步的问题:加锁
mutex 互斥量:
1 | pthread_mutex_t fastmutex = PTHREAD_MUTEX_INITIALIZER; // 常量初始化,此时可以使用init |
读写锁的特点:读共享,写独占,写优先级高
读写说任然是一把锁,有不同状态:
- 未加锁
- 读锁
- 写锁
1 | int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, |
条件变量(生产者消费者模型):
1 | pthread_cond_t cond = PTHREAD_COND_INITIALIZER; |
信号量 加强版的互斥锁:
信号量是进化版的互斥量,允许多个线程访问共享资源
1 |
|
文件锁:
1 |
|