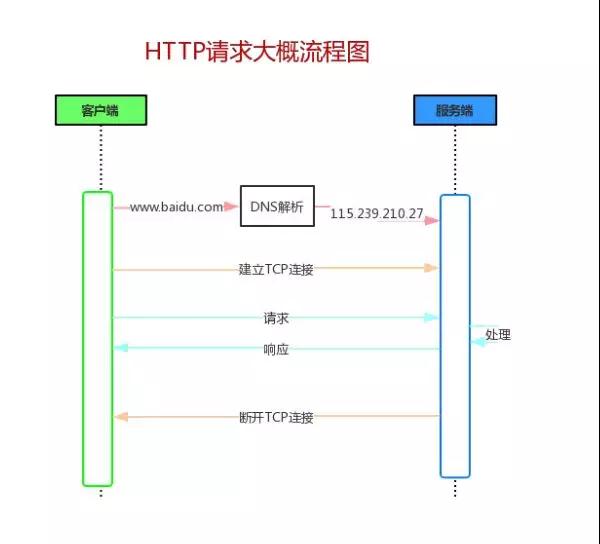
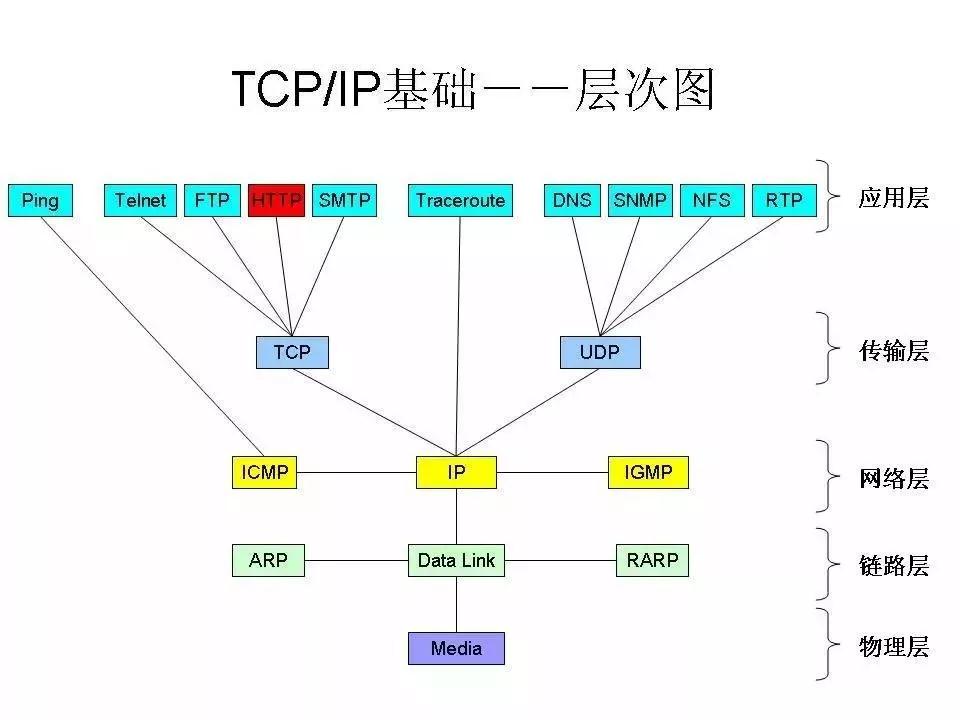
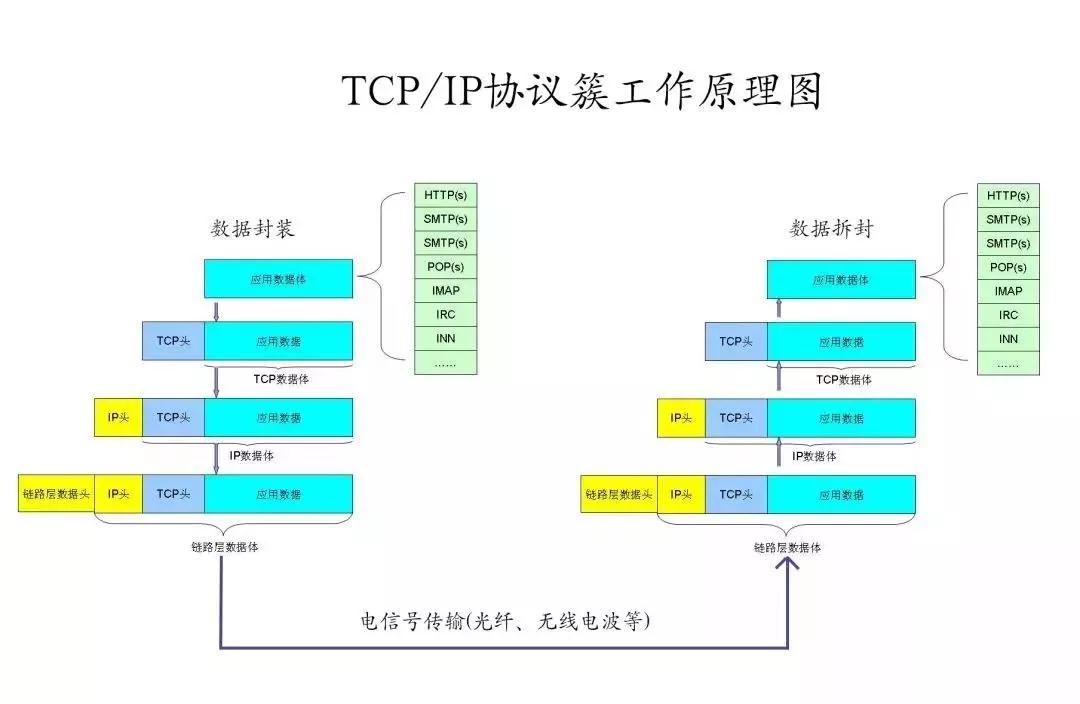
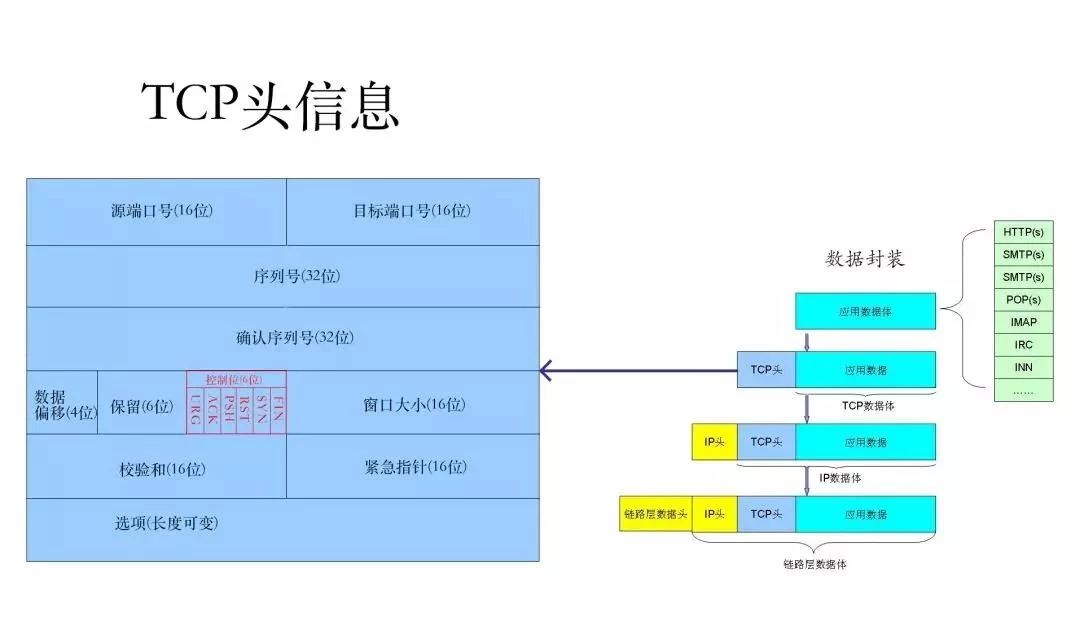
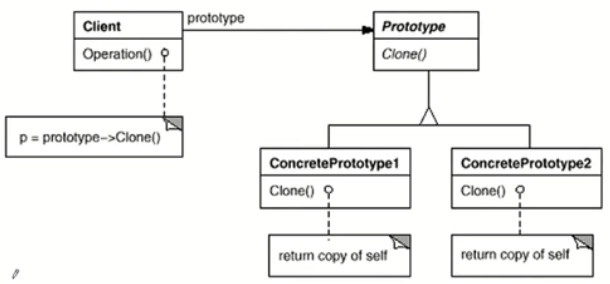
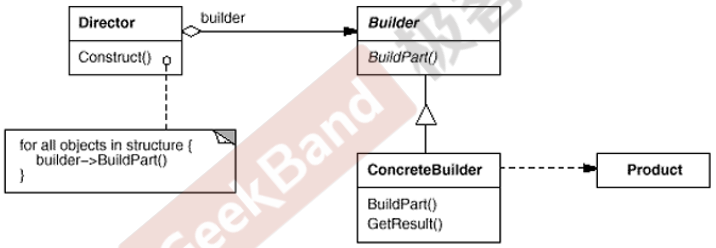
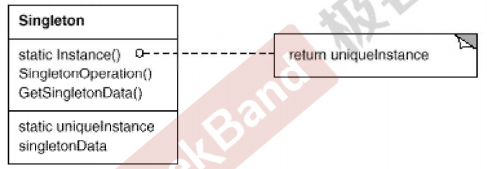
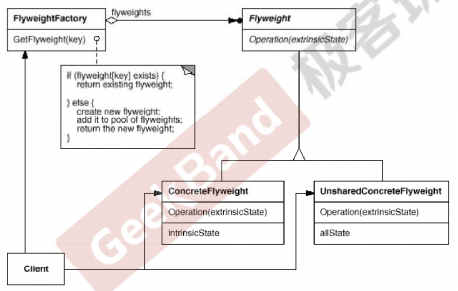
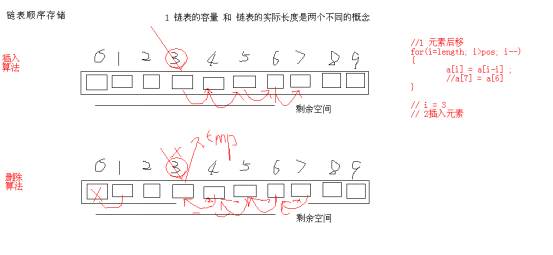
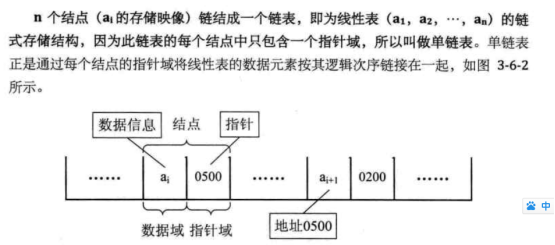
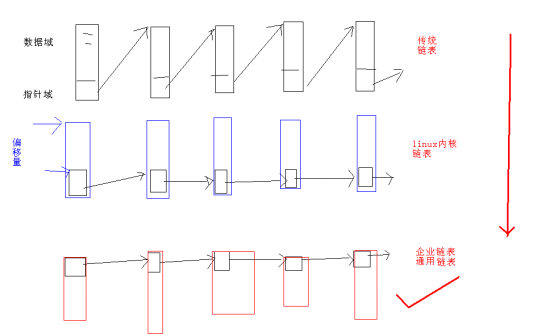
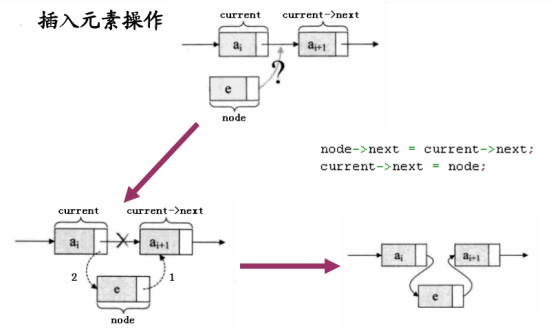
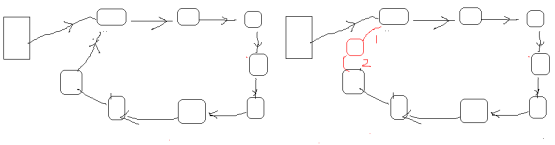
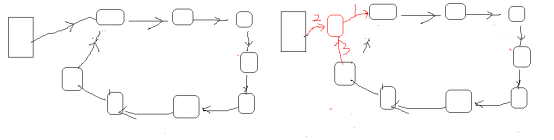
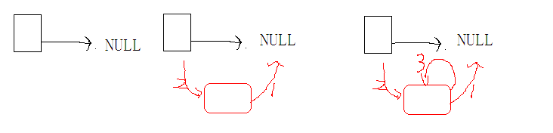
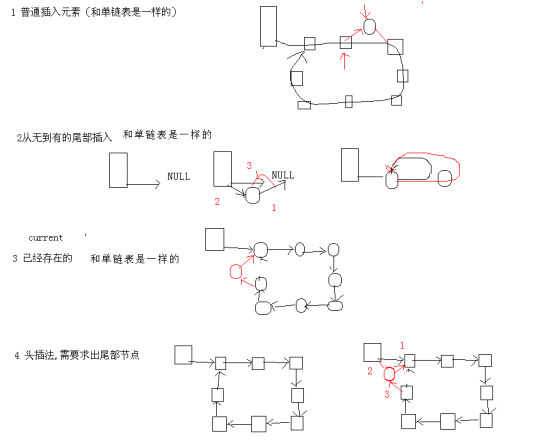
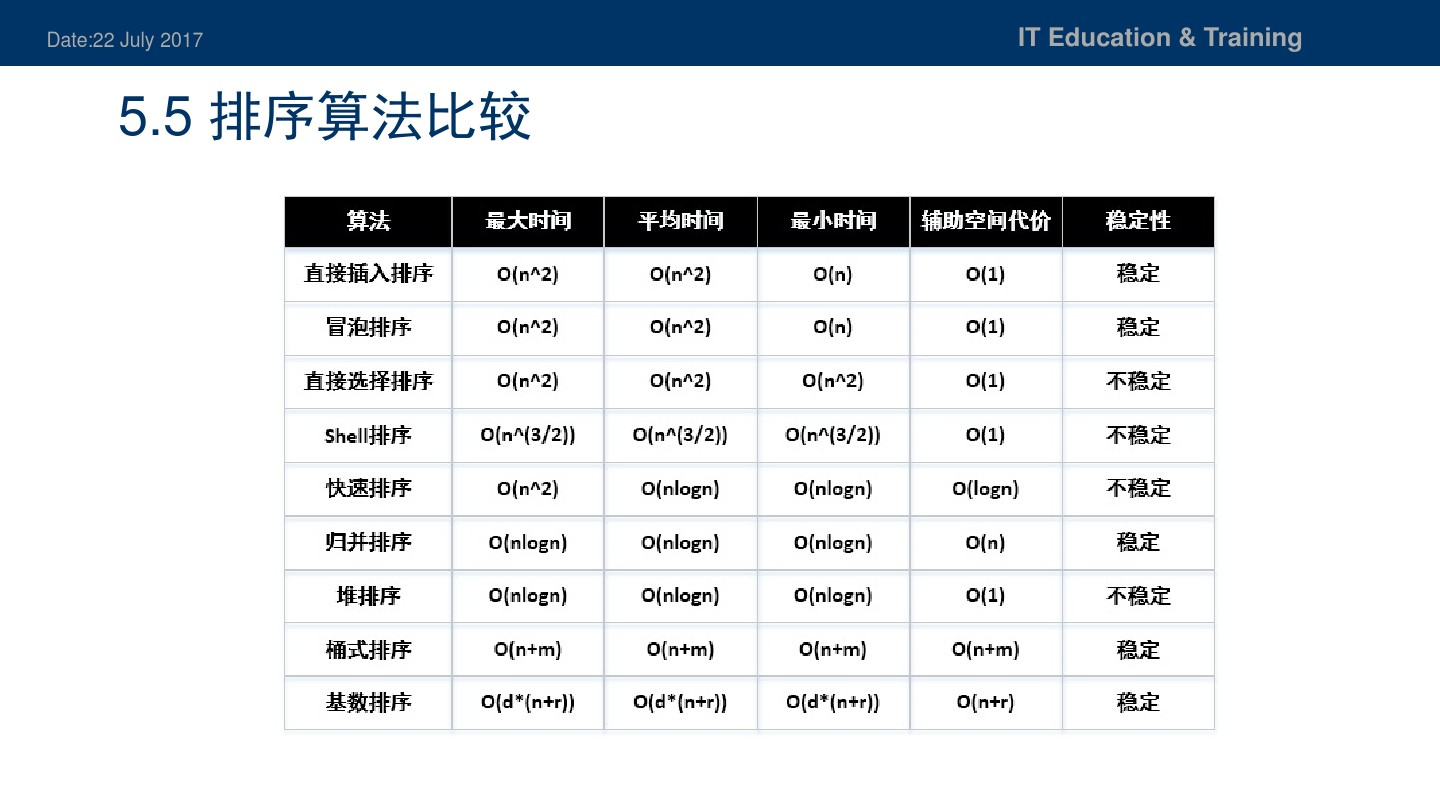
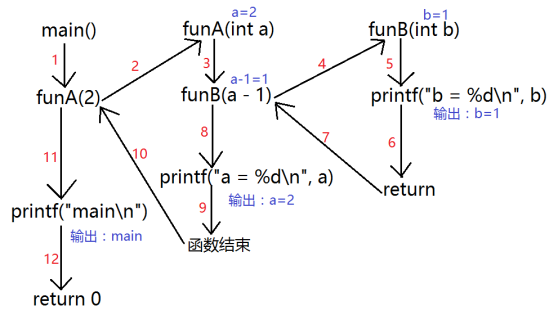
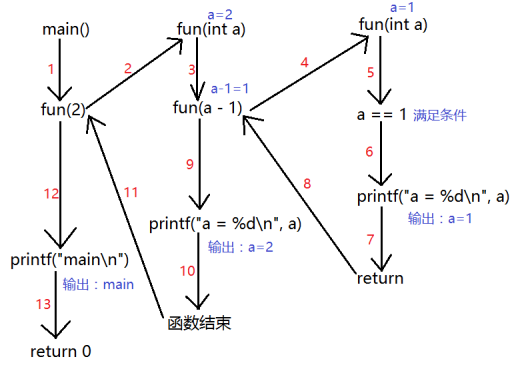
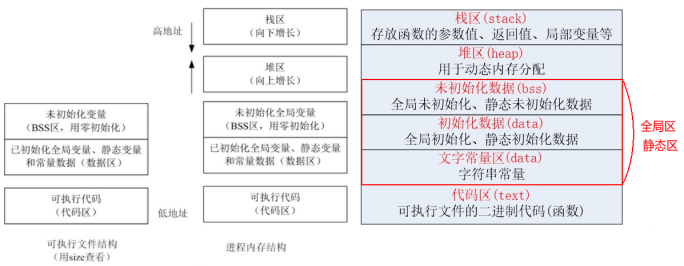
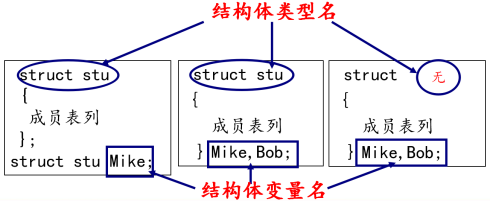
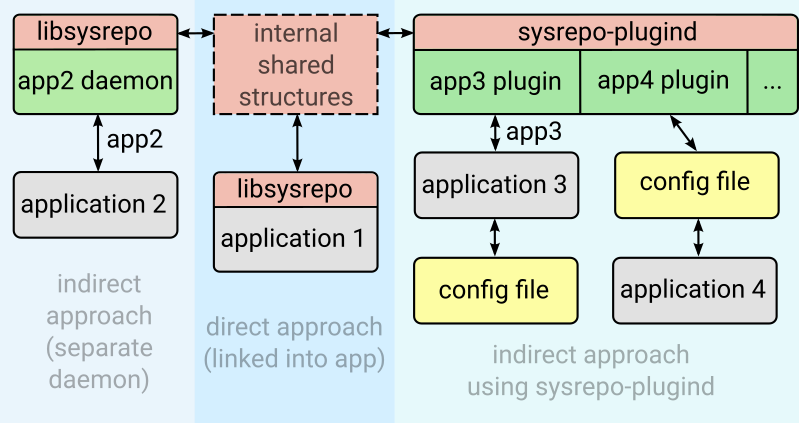
Mr.Miaow BlogDo what you say, say what you do.2020-09-23T07:50:35.462Zhttp://miaopei.github.io/Mr.MiaowHexosysrepo notehttp://miaopei.github.io/2020/09/23/Netconf/sysrepo-note/2020-09-23T11:50:28.000Z2020-09-23T07:50:35.462Zsysrepo
sysrepo - 1.4.2 笔记
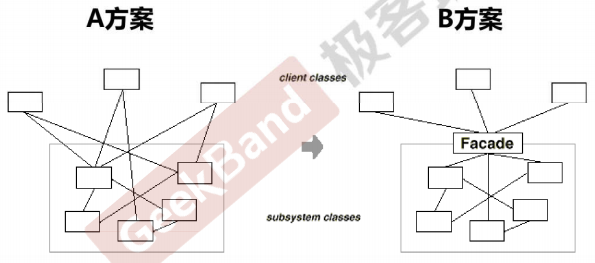
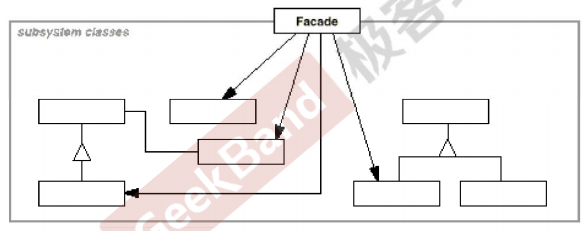
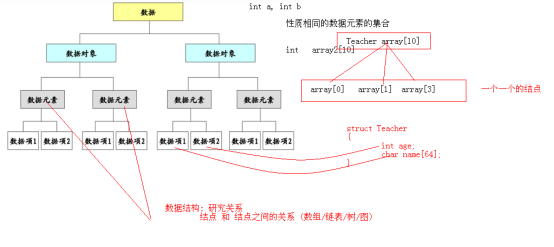
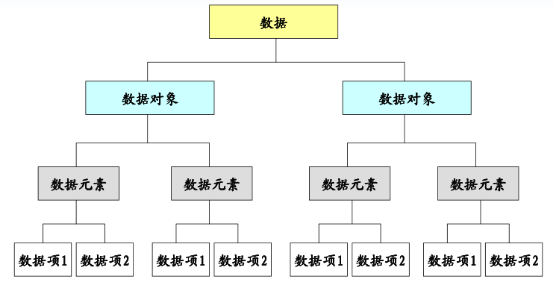
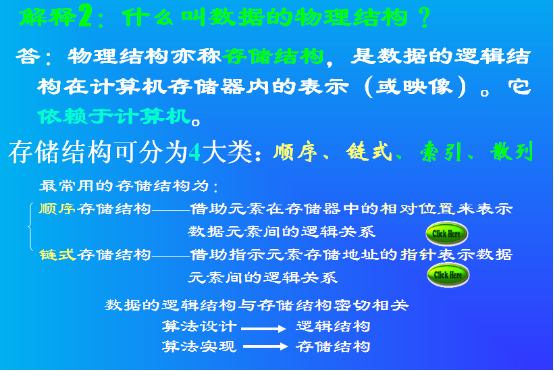
1. sysrepo 概述
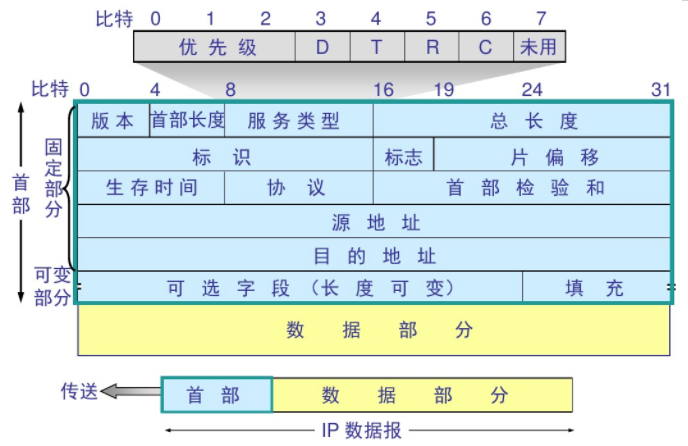
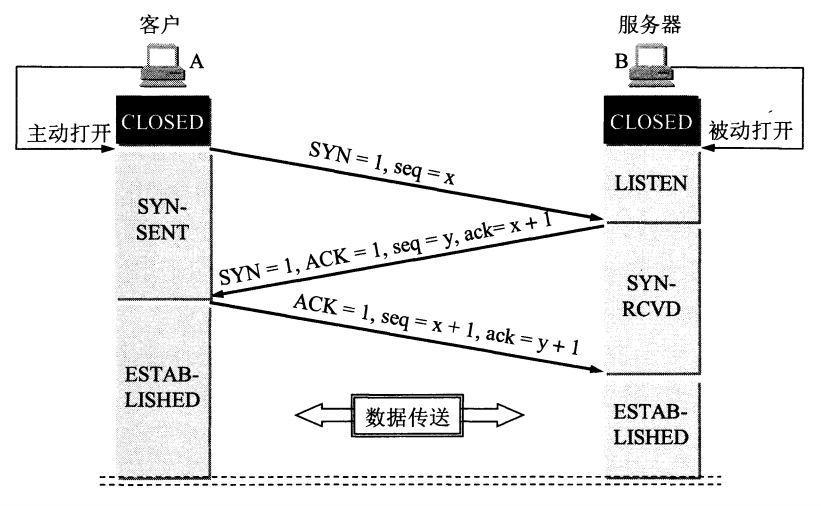
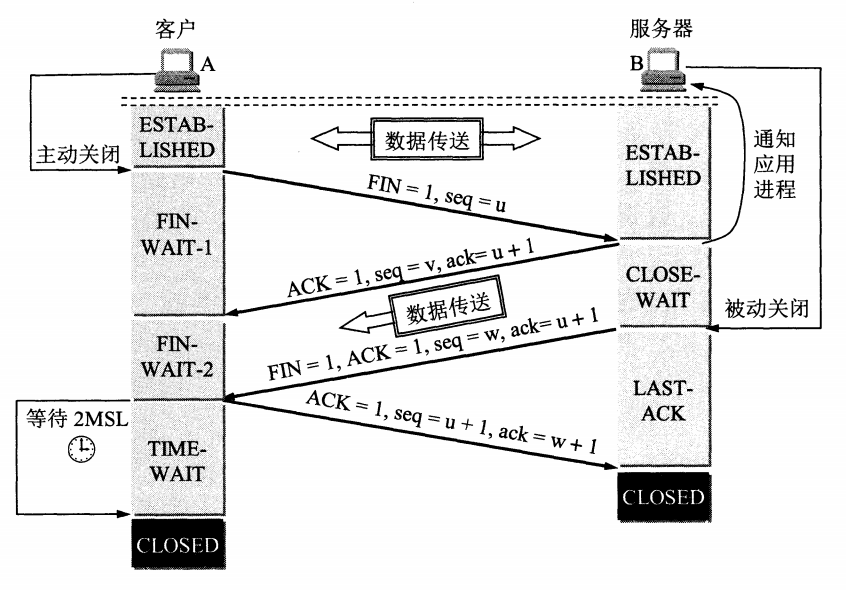
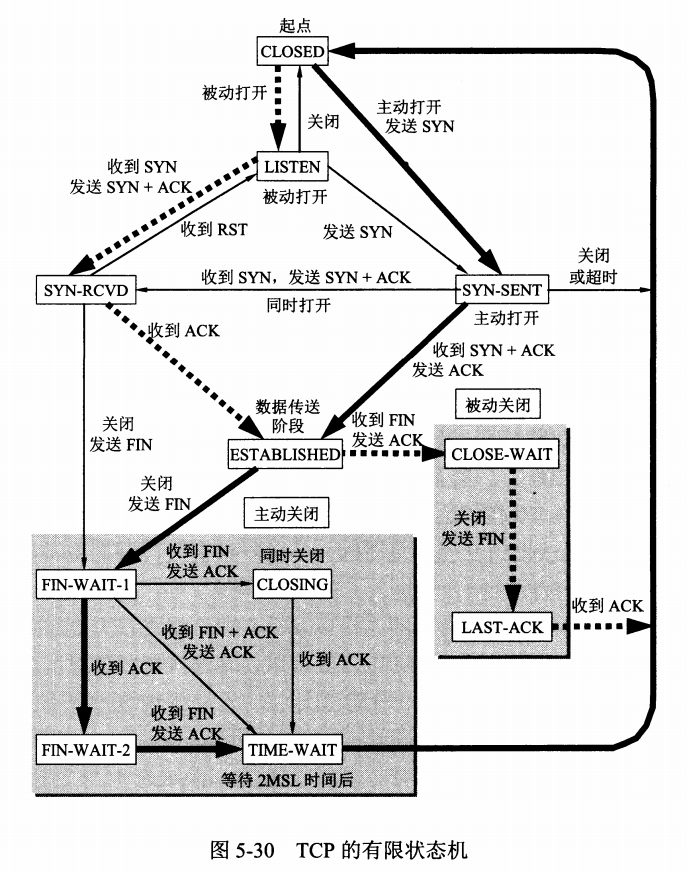
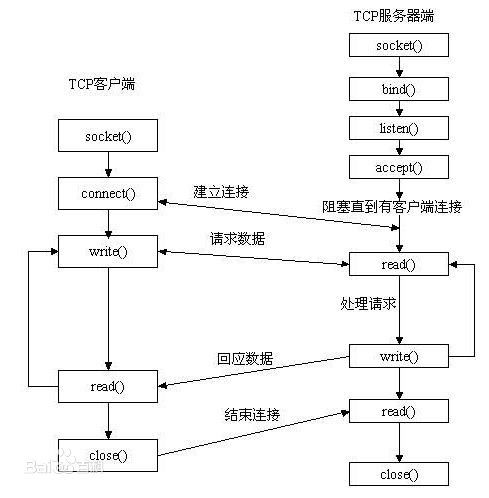
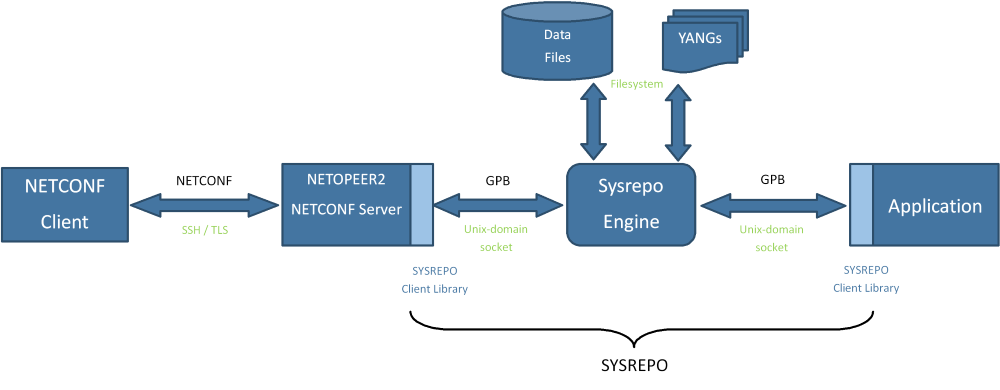
Sysrepo 是 Linux/Unix 系统下一个基于 YANG 模型的配置和操作数据库,为应用程序提供统一的操作数据的接口。应用程序使用 YANG 模型来建模,通过利用 YANG 模型完成数据合法性的检查,保证的风格的一致,不需要应用程序直接操作配置文件的一种数据管理方式。
1.1 基本特性与原则
sysrepo 只是一个库,不是一个独立的进程
全部的数据始终由 Yang 模型区分,这就可能造成许多严重的后果,例如,允许同时使用不同的模型进行工作,这将可 导致数据访问时异常。
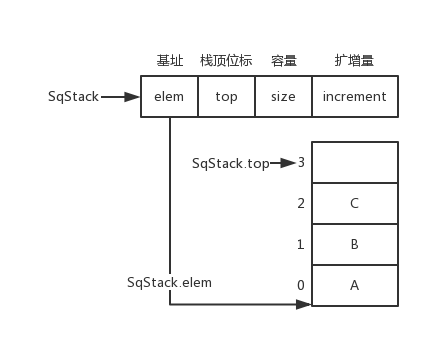
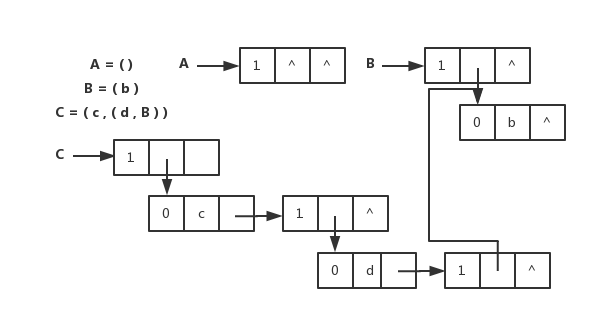
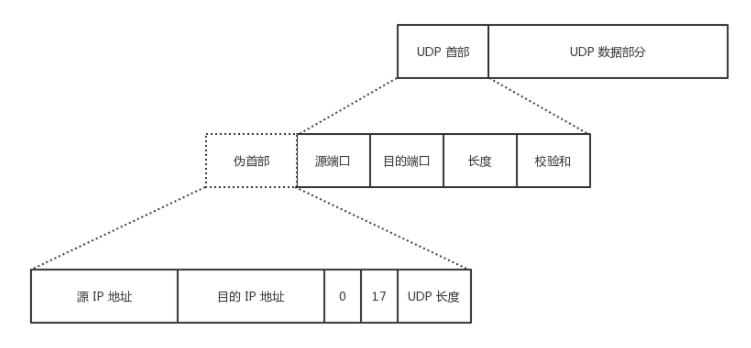
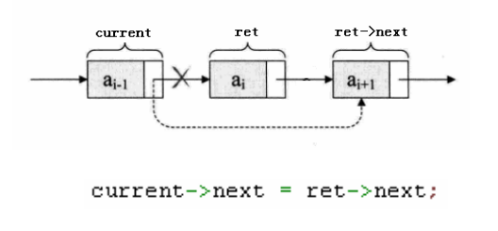
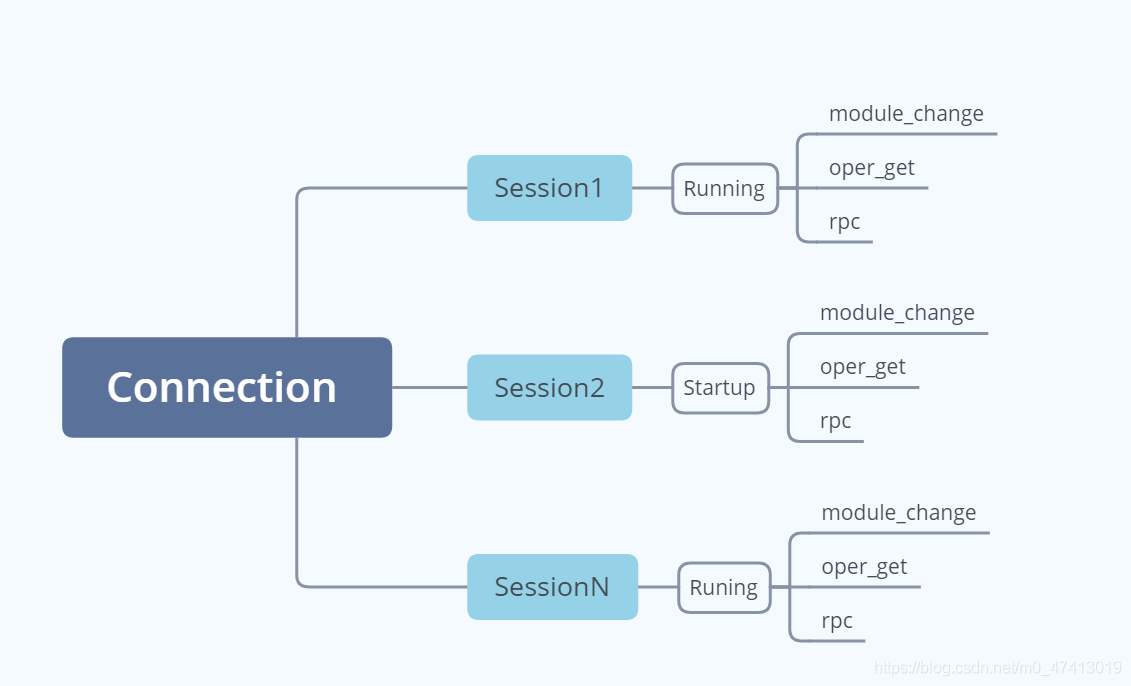
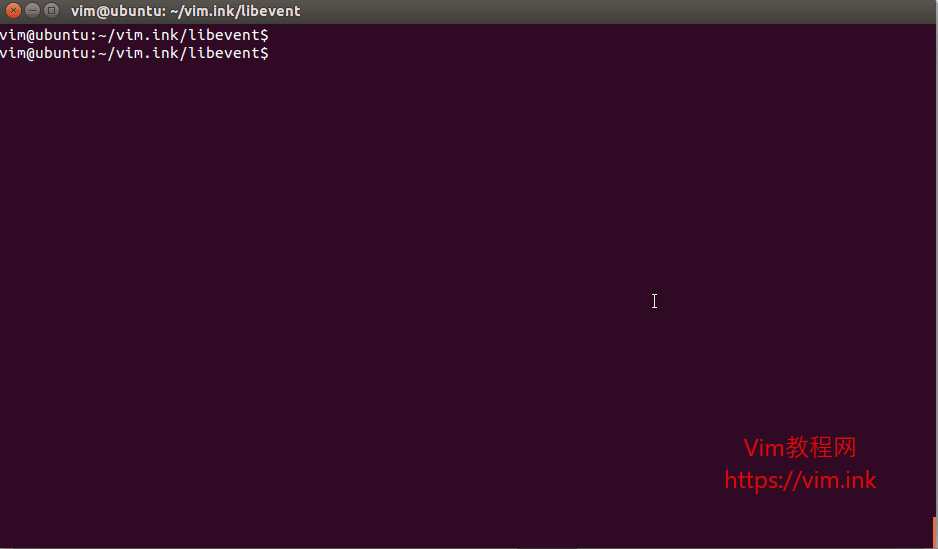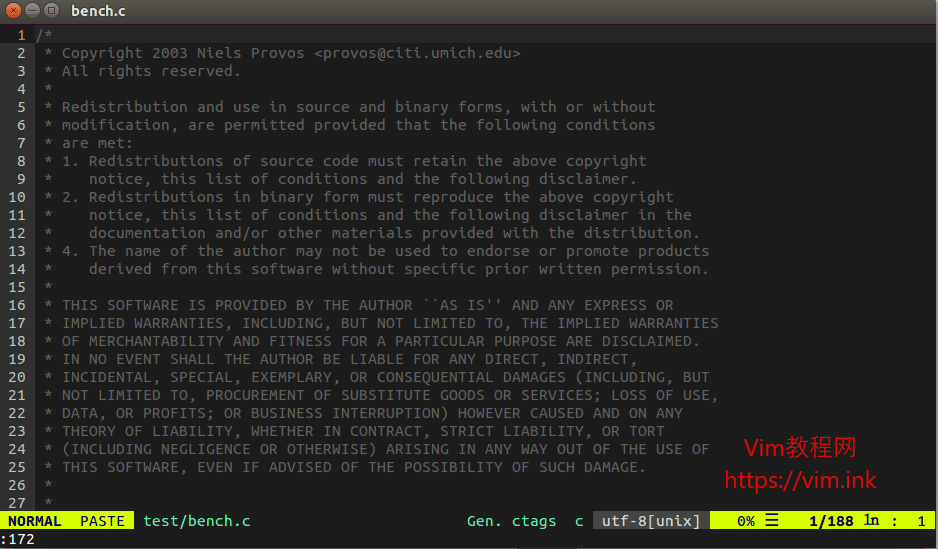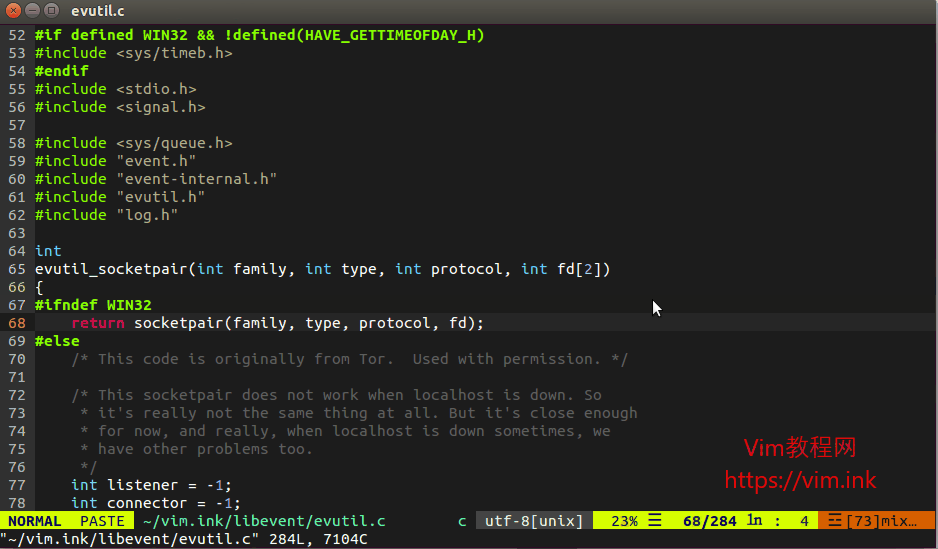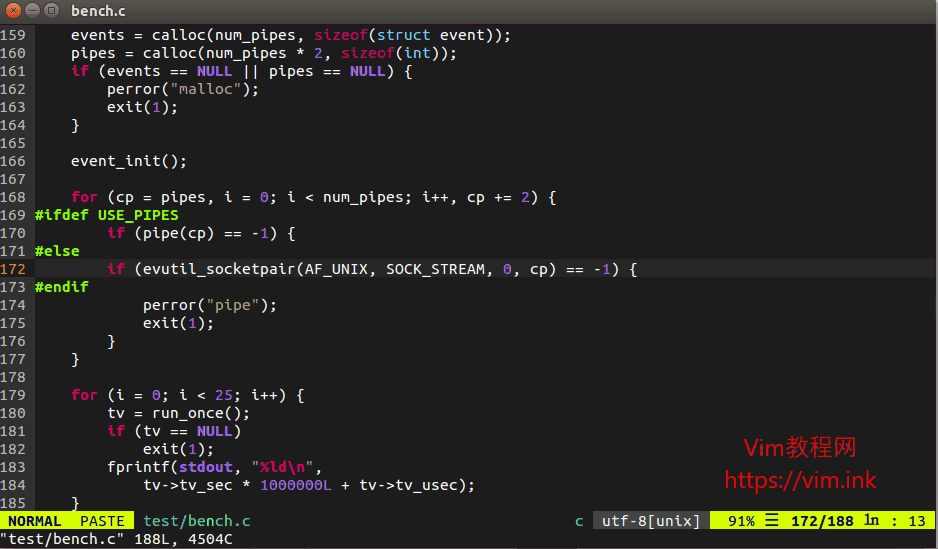
/*功能:开始一个新的session *输入:conn: 由sr_connect所创建的连接 * datastore: 连接的数据库类型 *输出: 用于后续的API调用的session上下文件 */ API int sr_session_start(sr_conn_ctx_t *conn, constsr_datastore_t datastore, sr_session_ctx_t **session) { sr_error_info_t *err_info = NULL; sr_main_shm_t *main_shm; uid_t uid; SR_CHECK_ARG_APIRET(!conn || !session, NULL, err_info); /*分配1个sizeof (**session)大小的内存空间,并初始化为0*/ *session = calloc(1, sizeof **session); if (!*session) { SR_ERRINFO_MEM(&err_info); return sr_api_ret(NULL, err_info); } /* use new SR session ID and increment it (no lock needed, we are just reading and main SHM is never remapped) */ /**使用了C++的atomic机制,在C中引入,需要增加编译选项,如何增加,参考CMakeFile.txt.*/ main_shm = (sr_main_shm_t *)conn->main_shm.addr; (*session)->sid.sr = ATOMIC_INC_RELAXED(main_shm->new_sr_sid); if ((*session)->sid.sr == (uint32_t)(ATOMIC_T_MAX - 1)) { /* the value in the main SHM is actually ATOMIC_T_MAX and calling another INC would cause an overflow */ ATOMIC_STORE_RELAXED(main_shm->new_sr_sid, 1); } /* remember current real process owner */ uid = getuid(); if ((err_info = sr_get_pwd(&uid, &(*session)->sid.user))) { goto error; } /* add the session into conn */ if ((err_info = sr_ptr_add(&conn->ptr_lock, (void ***)&conn->sessions, &conn->session_count, *session))) { goto error; } (*session)->conn = conn; (*session)->ds = datastore; if ((err_info = sr_mutex_init(&(*session)->ptr_lock, 0))) { goto error; } if ((err_info = sr_rwlock_init(&(*session)->notif_buf.lock, 0))) { goto error; } SR_LOG_INF("Session %u (user \"%s\") created.", (*session)->sid.sr, (*session)->sid.user); return sr_api_ret(NULL, NULL); error: free((*session)->sid.user); free(*session); *session = NULL; return sr_api_ret(NULL, err_info); }
$ git clone http://git.libssh.org/projects/libssh.git $cd libssh; mkdir build; cd build $ cmake .. $ make # make install # or $ wget https://git.libssh.org/projects/libssh.git/snapshot/libssh-0.7.5.tar.gz $ tar -xzf libssh-0.7.5.tar.gz $ mkdir libssh-0.7.5/build && cd libssh-0.7.5/build $ cmake -DCMAKE_INSTALL_PREFIX:PATH=/usr/local .. && make && sudo make install $cd ../..
$ git clone git://git.cryptomilk.org/projects/cmocka.git $cd cmocka $ git checkout tags/cmocka-1.0.1 $ mkdir build; cd build $ cmake .. $ make # make install
$ git clone https://github.com/CESNET/libnetconf2.git $ mkdir build; cd build $ cmake .. $ make # install $ make doc
2.3 安装 sysrepo
1 2 3 4 5 6 7
$ git clone https://github.com/sysrepo/sysrepo.git $ mkdir build; cd build $ cmake -DCMAKE_BUILD_TYPE=Debug .. $ make # make install $ make doc $ google-chrome ../doc/html/index.html
3. netopper2 安装
1 2 3 4 5 6 7
$ git clone https://github.com/CESNET/Netopeer2.git $cd Netopeer2 $export LD_LIBRARY_PATH=/usr/local/lib64:/usr/local/lib $ mkdir build && cd build $ cmake .. $ make $ sudo make install
libyang 简介
libyang doc
1. About
libyang is a library implementing processing of the YANG schemas and data modeled by the YANG language. The library is implemented in C for GNU/Linux and provides C API.
Libyang 是一个用 YANG 语言实现 YANG 模式和数据处理的库。该库是用 c 语言为 GNU/Linux 实现的,并提供了 c API。
2. Main Features
YANG 格式模式的解析(和验证)。
YIN 格式模式的解析(和验证)。
解析、验证和打印 XML 格式的实例数据。
解析、验证和打印 JSON 格式的实例数据 (RFC 7951)。
操作实例数据。
支持实例数据中的默认值 (RFC 6243)。
支持 YANG 扩展和用户类型。
支持 YANG 元数据 (RFC 7952)。
yanglint - 特征丰富的 YANG 工具
当前的实现包括 YANG 1.0 (RFC 6020) 和 YANG 1.1 (RFC 7950)。
3. Extra (side-effect) Features
XML 解析器。
优化字符串存储 (字典)。
libnetconf2 简介
1. About
libnetconf2 is a NETCONF library in C handling NETCONF authentication and all NETCONF RPC communication both server and client-side. Note that NETCONF datastore implementation is not a part of this library. The library supports both NETCONF 1.0 (RFC 4741) as well as NETCONF 1.1 (RFC 6241).
module oven { namespace "urn:sysrepo:oven"; prefix ov; revision 2018-01-19 { description "Initial revision."; } typedef oven-temperature { description "Temperature range that is accepted by the oven."; type uint8 { range "0..250"; } } container oven { description "Configuration container of the oven."; leaf turned-on { description "Main switch determining whether the oven is on or off."; type boolean; default false; } leaf temperature { description "Slider for configuring the desired temperature."; type oven-temperature; default 0; } } container oven-state { description "State data container of the oven."; config false; leaf temperature { description "Actual temperature inside the oven."; type oven-temperature; } leaf food-inside { description "Informs whether the food is inside the oven or not."; type boolean; } } rpc insert-food { description "Operation to order the oven to put the prepared food inside."; input { leaf time { description "Parameter determining when to perform the operation."; type enumeration { enum now { description "Put the food in the oven immediately."; } enum on-oven-ready { description "Put the food in once the temperature inside the oven is at least the configured one. If it is already, the behaviour is similar to 'now'."; } } } } } rpc remove-food { description "Operation to order the oven to take the food out."; } notification oven-ready { description "Event of the configured temperature matching the actual temperature inside the oven. If the configured temperature is lower than the actual one, no notification is generated when the oven cools down to the configured temperature."; } }
$ snmptrap -v1 -c public 192.168.2.124 .1.3.6.1.4.1.1 192.168.2.125 6 10 100 1.3.6.1.9.9.44.1.2.1 i 12 # 命令 版本 -c 共同体 TrapServerIP Enterprise-OID AgentIP 陷阱类型 oid 时间 被发送参数的OID 数据类型 值
# i 整形 u 无符号型 c COUNTER32 s 字符串 x 16进制字符串 d 10进制字符串 n 空对象 o 对象ID t 计时器 a IP地址 b 比特 # Generic Type包括7种, 分别是: # 0 coldStart 1 warmStart 2 linkDown 3 linkUp 4 authenticationFailure 5 egpNeighborLoss 6 enterpriseSpecific
$ netopeer-manager list Reading the configuration from /usr/local/etc/netopeer/modules.conf.d/ List of startup Netopeer modules: turing-machine (enabled)
$ sudo /usr/local/bin/netopeer-server -v 3 $ sudo /usr/local/bin/netopeer-cli netconf>help # Available commands: #help Display this text # connect Connect to a NETCONF server # listen Listen for a NETCONF Call Home # disconnect Disconnect from a NETCONF server # commit NETCONF <commit> operation # copy-config NETCONF <copy-config> operation # delete-config NETCONF <delete-config> operation # discard-changes NETCONF <discard-changes> operation # edit-config NETCONF <edit-config> operation # get NETCONF <get> operation # get-config NETCONF <get-config> operation # get-schema NETCONF <get-schema> operation #kill-session NETCONF <kill-session> operation # lock NETCONF <lock> operation # unlock NETCONF <unlock> operation # validate NETCONF <validate> operation #test Run a specified testcase # subscribe NETCONF Event Notifications <create-subscription> operation # time Enable/disable measuring time of command execution # knownhosts Manage known hosts in the "~/.ssh/known_hosts" file # status Print information about the current NETCONF session # user-rpc Send your own content in an RPC envelope (for DEBUG purposes) # verbose Enable/disable verbose messages # quit Quit the program # auth Manage SSH authentication options # capability Add/remove capability to/from the list of supported capabilities # editor Manage the editor to be used for manual XML pasting/writing netconf> connect 127.0.0.1 netconf> get -h # get [--help] [--defaults report-all|report-all-tagged|trim|explicit] [--filter [file]] [--out file] netconf> get --filter=/root/turing.xml netconf> get-config -h # get-config [--help] [--defaults report-all|report-all-tagged|trim|explicit] [--filter [file]] [--out file] running|startup|candidate
netconf> get-config --filter=/root/turing.xml candidate netconf> edit-config -h # edit-config [--help] [--defop <merge|replace|none>] [--error <stop|continue|rollback>] [--test <set|test-only|test-then-set>] [--config <file> | --url <url>] running|startup|candidate # If neither --config nor --url is specified, user is prompted to set edit data manually. netconf> lock candidate netconf> debug netconf> edit-config --defop=merge --config=/root/turing.xml candidate netconf> commit netconf> unlock candidate netconf> netconf> user-rpc --file=/root/rpc-run.xml
If already installed, make sure that pip/setuptools are upto date (commands may vary) pip install --upgrade pip Ubuntu: sudo pip install --upgrade setuptools
$ git clone https://github.com/CiscoDevNet/yang-explorer.git $cd yang-explorer $ bash setup.sh # Note: sudo may be required if you do not use virtualenv.
有关更多信息,请参见第 7节疑难解答:
1 2 3 4
If you get installation error for missing python.h or xmlversion.h try installing dependency packages: Ubuntu: sudo apt-get install libxml2-dev libxslt1-dev python-dev zlib1g-dev Fedora: sudo dnf install libxml2-devel libxslt-devel python-devel zlib-devel
更新 exising 安装
1 2 3 4 5
$cd<install-root>/yang-explorer $ git stash (if you have local changes) $ git pull origin $ git stash apply (if you have local changes) $ bash setup.sh
$cd<install-root>/yang-explorer/server # move current data to tmp location mv data data_old # replace data from backup location cp -r <backup-location>/data data
运行 YangExplorer, localhost Start 服务器:
1 2 3
$cd<install-root>/yang-explorer $ [sudo]./start.sh & # Note: sudo may be required if you did not use virtualenv during installation.
Start 资源管理器:
1
http://localhost:8088/static/YangExplorer.html
运行 ip 地址( 共享服务器) Start 服务器
1 2 3 4 5 6 7 8 9
# Determine <ip-address> using if-config# Add ip-address/port in YangExplorer.html after following line:cd<install-root>/yang-explorer/server/static $ vi YangExplorer.html var flashvars = {}; + flashvars.host = '<ip-address>';+ flashvars.port = '8088'; # save & quit# Update ip-address in startup scriptcd<install-root>/yang-explorer $ vi start.sh (update HOST variable with <ip-address>) # save & quit. /start.sh # Note: sudo may be required if you did not use virtualenv during installation.
Start 资源管理器:
1
http://<ip-address>:8088/static/YangExplorer.html
virtual python env
创建 virtual python env
python环境神器virtualenvwrapper安装与使用
Reference
模块下载地址
[ Libnetconf文档网站 ]
[ Netopeer项目 ]
[ Libnetconf项目 ]
[ Pyang项目 ]
[ Libssh项目 ]
模块编译安装
NETCONF协议netopeer软件安装与环境搭建
Set up Netopeer Server to use with NETCONFc
NETCONF协议之netopeer软件安装
netconf学习资料
软件定义网络基础—NETCONF协议
Netconf配置及其RPC和Notification下发流程解析
NETCONF协议详解
NETCONF模块设计介绍
netopeer工具的使用
【开源推介02-pyang】-你离yang模型只差一个pyang工具
netconf相关问题解决
An error occurred after executing the ‘commit‘’ command
cannot execute lock/unlock from netopeer-cli
YANG Tools:Yang1.1 Draft Yang Tools: Yang1.1 Draft
5 Git workflows you can use to deliver better code and improve your development process
I haven’t met a developer who looked at a conflict message and did not pull their hair strands with frustration.
Trying to resolve each merge conflict is one of those things that every developer hates. Especially if it hits you when you’re gearing up for a production deploy!
This is where having the right Git workflow set up can do a world of good for your development workflow.
Of course, having the right git workflow will not solve all your problems. But it’s a step in the right direction. After all, with every team working remotely, the need to build features together without having your codebase getting disrupted is critical.
How you set it up depends on the project you’re working on, the release schedules your team has, the size of the team, and more!
In this article, we’ll walk you through 5 different git workflows, their benefits, their cons, and when you should use them. Let’s jump in!
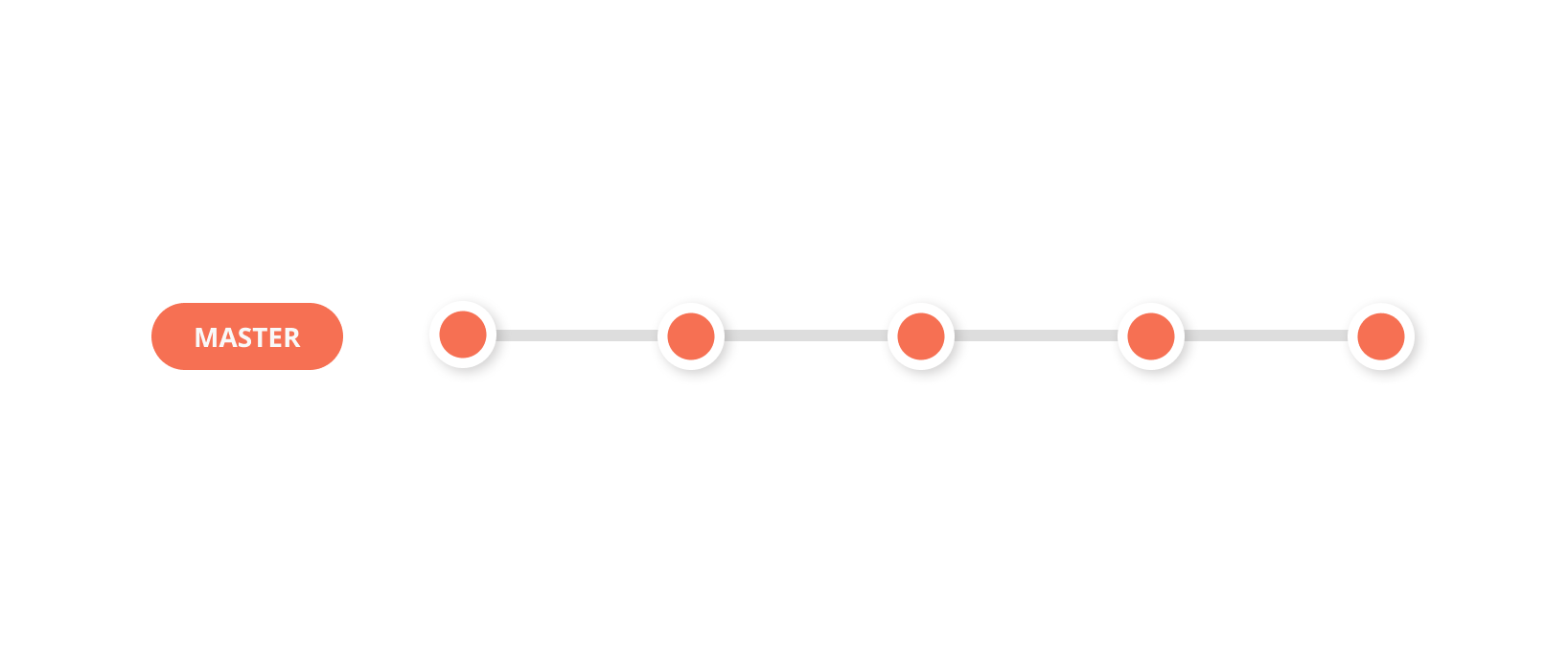
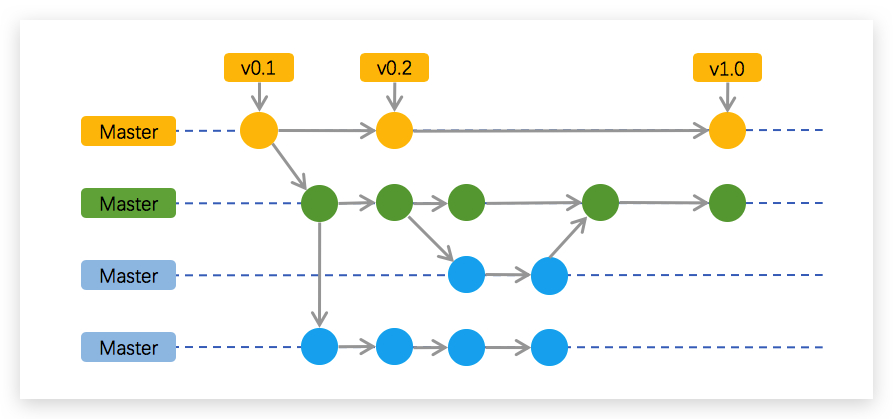
1. Basic Git Workflow
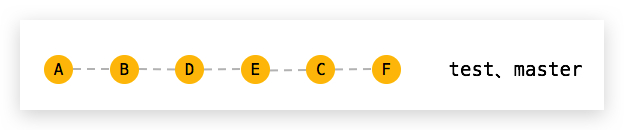
The most basic git workflow is the one where there is only one branch — the master branch. Developers commit directly into it and use it to deploy to the staging and production environment.
This workflow isn’t usually recommended unless you’re working on a side project and you’re looking to get started quickly.
Since there is only one branch, there really is no process over here. This makes it effortless to get started with Git. However, some cons you need to keep in mind when using this workflow are:
Collaborating on code will lead to multiple conflicts.
Chances of shipping buggy software to production is higher.
Maintaining clean code is harder.
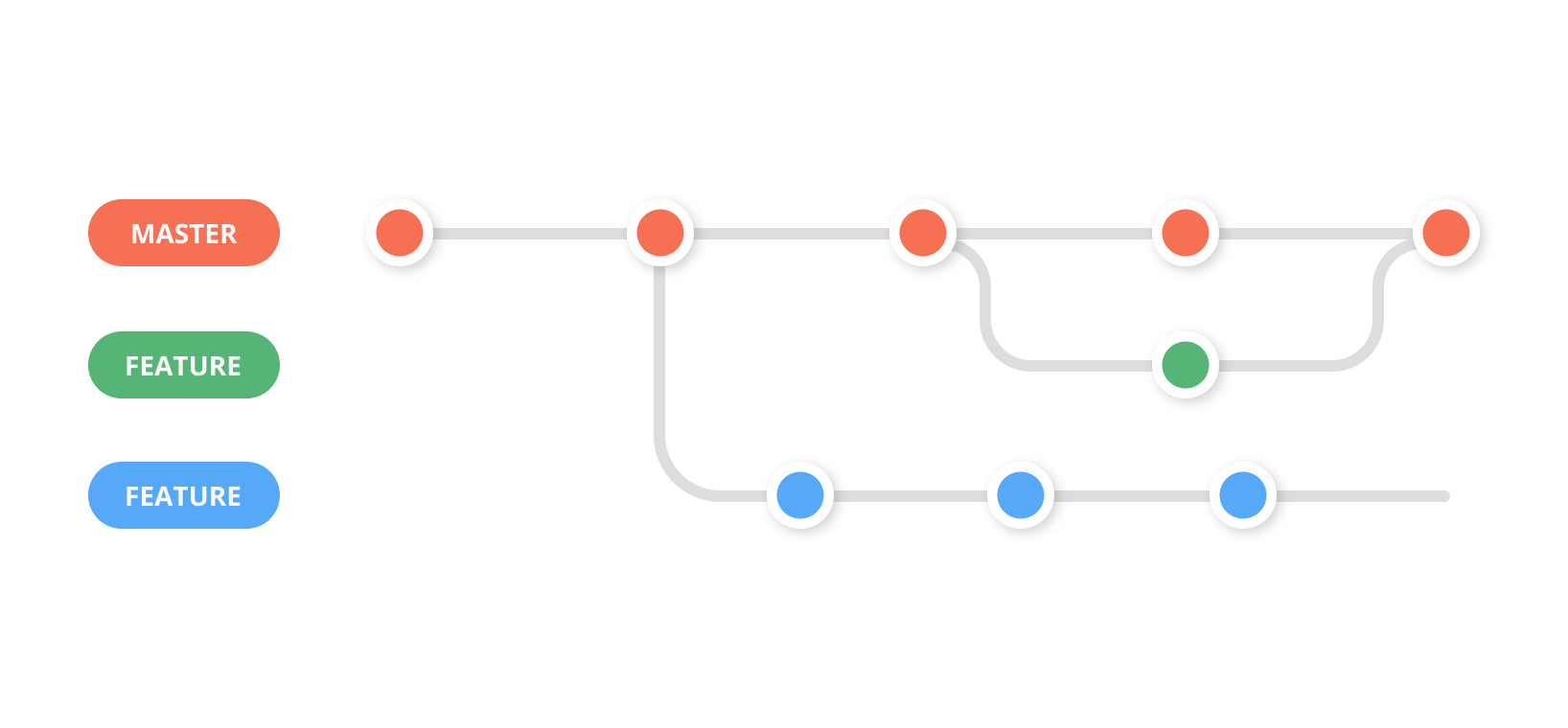
2. Git Feature Branch Workflow
The Git Feature Branch workflow becomes a must have when you have more than one developer working on the same codebase.
Imagine you have one developer who is working on a new feature. And another developer working on a second feature. Now, if both the developers work from the same branch and add commits to them, it would make the codebase a huge mess with plenty of conflicts.
To avoid this, the two developers can create two separate branches from the master branch and work on their features individually. When they’re done with their feature, they can then merge their respective branch to the master branch, and deploy without having to wait for the second feature to be completed.
The Pros of using this workflow is, the git feature branch workflow allows you to collaborate on code without having to worry about code conflicts.
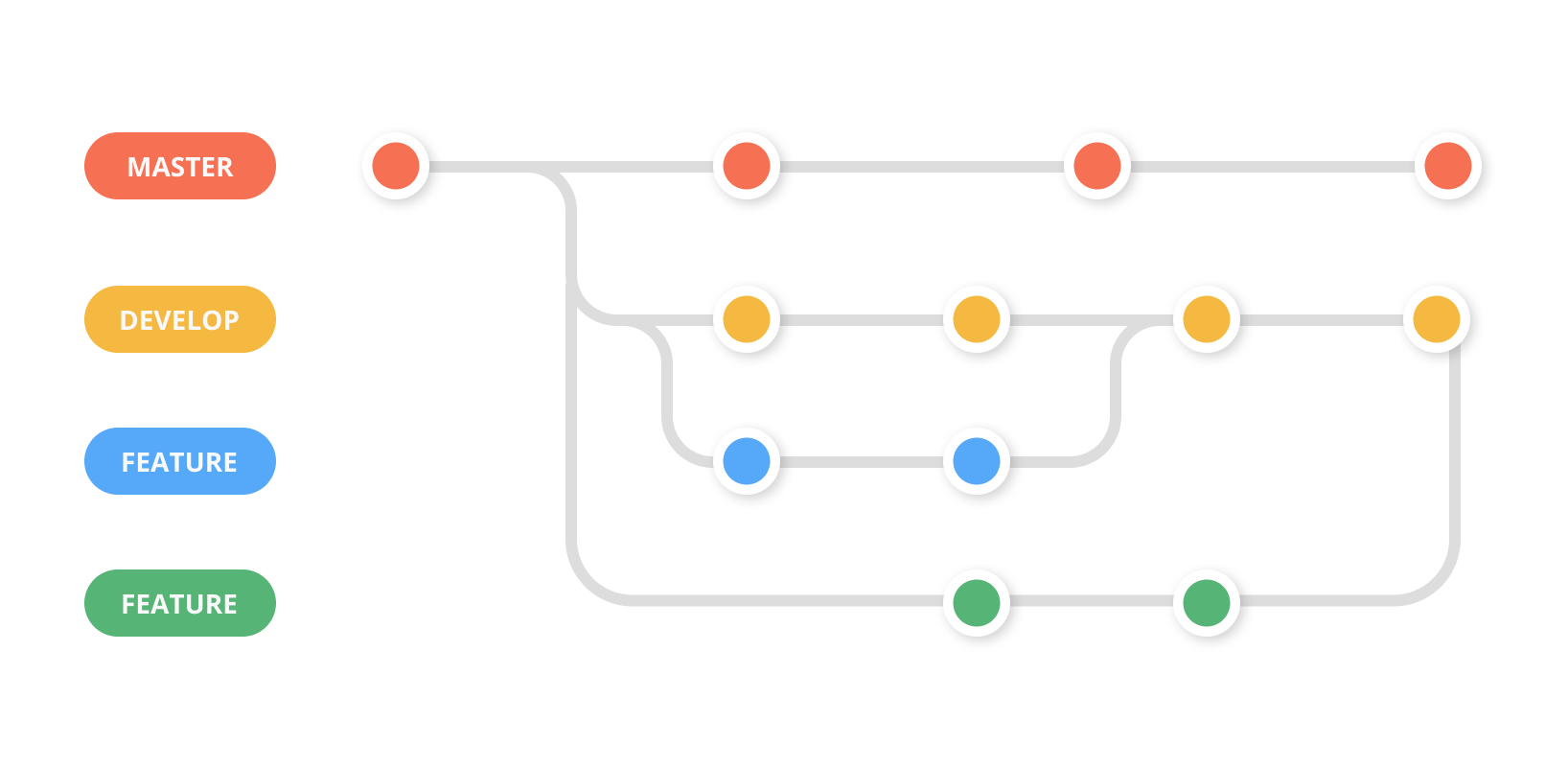
3. Git Feature Workflow with Develop Branch
This workflow is one of the more popular workflows among developer teams. It’s similar to the Git Feature Branch workflow with a develop branch that is added in parallel to the master branch.
In this workflow, the master branch always reflects a production-ready state. Whenever the team wants to deploy to production they deploy it from the master branch.
The develop branch reflects the state with the latest delivered development changes for the next release. Developers create branches from the develop branch and work on new features. Once the feature is ready, it is tested, merged with develop branch, tested with the develop branch’s code in case there was a prior merge, and then merged with master.
The advantage of this workflow is, it allows teams to consistently merge new features, test them in staging, and deploy to production. While maintaining code is easier, it can get a little tiresome for some teams since it can feel like going through a tedious process.
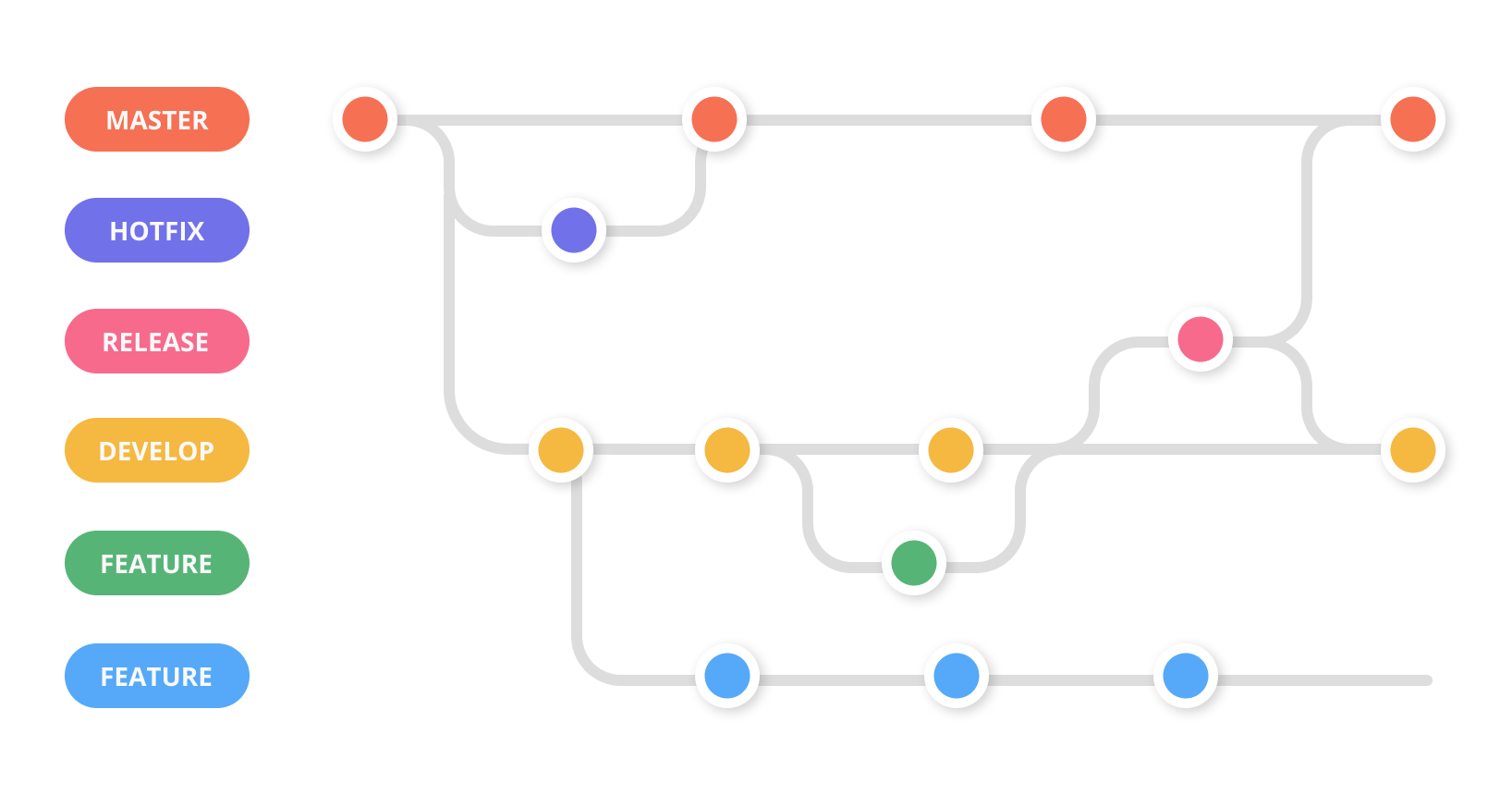
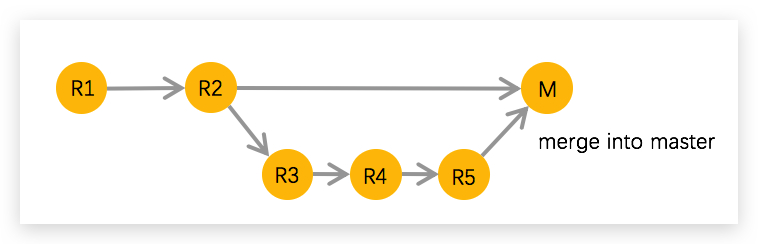
4. Gitflow Workflow
The gitflow workflow is very similar to the previous workflow we discussed combined with two other branches — the release branch and the hot-fix branch.
The hot-fix branch
The hot-fix branch is the only branch that is created from the master branch and directly merged to the master branch instead of the develop branch. It is used only when you have to quickly patch a production issue. An advantage of this branch is, it allows you to quickly deploy a production issue without disrupting others’ workflow or without having to wait for the next release cycle.
Once the fix is merged into the master branch and deployed, it should be merged into both develop and the current release branch. This is done to ensure that anyone who forks off develop to create a new feature branch has the latest code.
The release branch
The release branch is forked off of develop branch after the develop branch has all the features planned for the release merged into it successfully.
No code related to new features is added into the release branch. Only code that relates the release is added to the release branch. For example, documentation, bug fixes, and other tasks related to this release are added to this branch.
Once this branch is merged with master and deployed to production, it’s also merged back into the develop branch, so that when a new feature is forked off of develop, it has the latest code.
This workflow was first published and made popular by Vincent Driessen and since then it has been widely used by organizations that have a scheduled release cycle.
Since the git-flow is a wrapper around Git, you can install git-flow in your current repository. It’s a straightforward process and it doesn’t change anything in your repository other than creating branches for you.
To install on a Mac machine, execute brew install git-flow in your terminal.
To install on a Windows machine, you’ll need to download and install the git-flow. After the installation is done, run git flow init to use it in your project.
5. Git Fork Workflow
The Fork workflow is popular among teams who use open-source software.
The flow usually looks like this:
The developer forks the open-source software’s official repository. A copy of this repository is created in their account.
The developer then clones the repository from their account to their local system.
A remote path for the official repository is added to the repository that is cloned to the local system.
The developer creates a new feature branch is created in their local system, makes changes, and commits them.
These changes along with the branch are pushed to the developer’s copy of the repository on their account.
A pull request from the branch is opened to the official repository.
The official repository’s manager checks the changes and approves the changes to get merged into the official repository.
]]>
<h1 id="Git-原理和常用命令"><a href="#Git-原理和常用命令" class="headerlink" title="Git 原理和常用命令"></a>Git 原理和常用命令</h1><h2 id="5-Git-workflows-you-can-use-to-deliver-better-code-and-improve-your-development-process"><a href="#5-Git-workflows-you-can-use-to-deliver-better-code-and-improve-your-development-process" class="headerlink" title="5 Git workflows you can use to deliver better code and improve your development process"></a>5 Git workflows you can use to deliver better code and improve your development process</h2><p>I haven’t met a developer who looked at a conflict message and did not pull their hair strands with frustration.</p>
优秀的Blog链接http://miaopei.github.io/2020/06/17/Other/优秀的Blog链接/2020-06-17T08:58:17.000Z2020-07-08T09:13:51.823Z前端
]]>
Welcome to my blog, enter password to read.
WebRTC 流媒体服务器(二)http://miaopei.github.io/2019/10/12/WebRTC/mediaserver-01/2019-10-12T02:56:03.000Z2020-05-21T08:17:46.476Z
]]>
Welcome to my blog, enter password to read.
WebRTC 流媒体服务器(一)http://miaopei.github.io/2019/10/09/WebRTC/mediaserver/2019-10-09T03:39:14.000Z2020-03-19T02:02:11.584Z
]]>
Welcome to my blog, enter password to read.
侯捷C++讲义http://miaopei.github.io/2019/09/03/Program-C/HouJieCPlus/2019-09-03T10:22:18.000Z2019-09-20T02:33:43.997Z面向对象高级编程 Part1
温馨提示:在 IntelliJ IDEA 中有两个 Mac 版本的快捷键,分别为 Mac OS X 和 Mac OS X 10.5+, 其中 Mac OS X 10.5+ 为 IntelliJ IDEA 默认的快捷键版本。此外,建议将 Mac 系统中与 IntelliJ IDEA 冲突的快捷键取消或更改,不建议改 IntelliJ IDEA 的默认快捷键。
]]>
<blockquote>
<p><strong>温馨提示</strong>:在 IntelliJ IDEA 中有两个 Mac 版本的快捷键,分别为 Mac OS X 和 Mac OS X 10.5+, 其中 Mac OS X 10.5+ 为 IntelliJ IDEA 默认的快捷
茶知识http://miaopei.github.io/2019/07/19/Other/tea/2019-07-19T11:14:50.000Z2019-07-24T03:55:28.075Z
]]>
Welcome to my blog, enter password to read.
webrtc-专题-01-WebRTC框架介绍http://miaopei.github.io/2019/06/16/WebRTC/webrtc-专题-01/2019-06-16T11:17:23.000Z2020-03-19T02:02:06.114Z
]]>
Welcome to my blog, enter password to read.
实时音视频互动系列http://miaopei.github.io/2019/06/09/WebRTC/01-实时音视频互动系列/2019-06-09T11:14:50.000Z2020-03-19T02:00:49.981Z
]]>
Welcome to my blog, enter password to read.
WebRTC视频统计信息之延迟抖动与丢包http://miaopei.github.io/2019/06/07/WebRTC/webrtc的视频统计信息之延迟抖动与丢包/2019-06-07T11:14:50.000Z2020-03-19T02:01:00.211Z
]]>
Welcome to my blog, enter password to read.
WebRTC 镜像源http://miaopei.github.io/2019/05/30/WebRTC/webrtc-src/2019-05-30T11:14:50.000Z2020-03-19T02:01:51.377Z
]]>
Welcome to my blog, enter password to read.
实用的计算机工具库http://miaopei.github.io/2019/05/29/Other/实用的计算机工具库/2019-05-29T02:14:50.000Z2019-06-27T05:09:36.497Z在我们平时的工作过程中,经常会用到各种工具,每次遇到问题都得各种百度搜索,今天给大家带来几个私藏多年的工具库,有了它,你再也不用到处找工具了,里面包含了大量的使用工具。
]]>
Welcome to my blog, enter password to read.
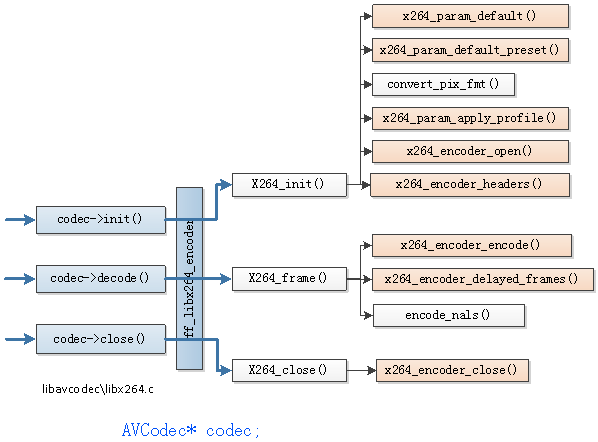
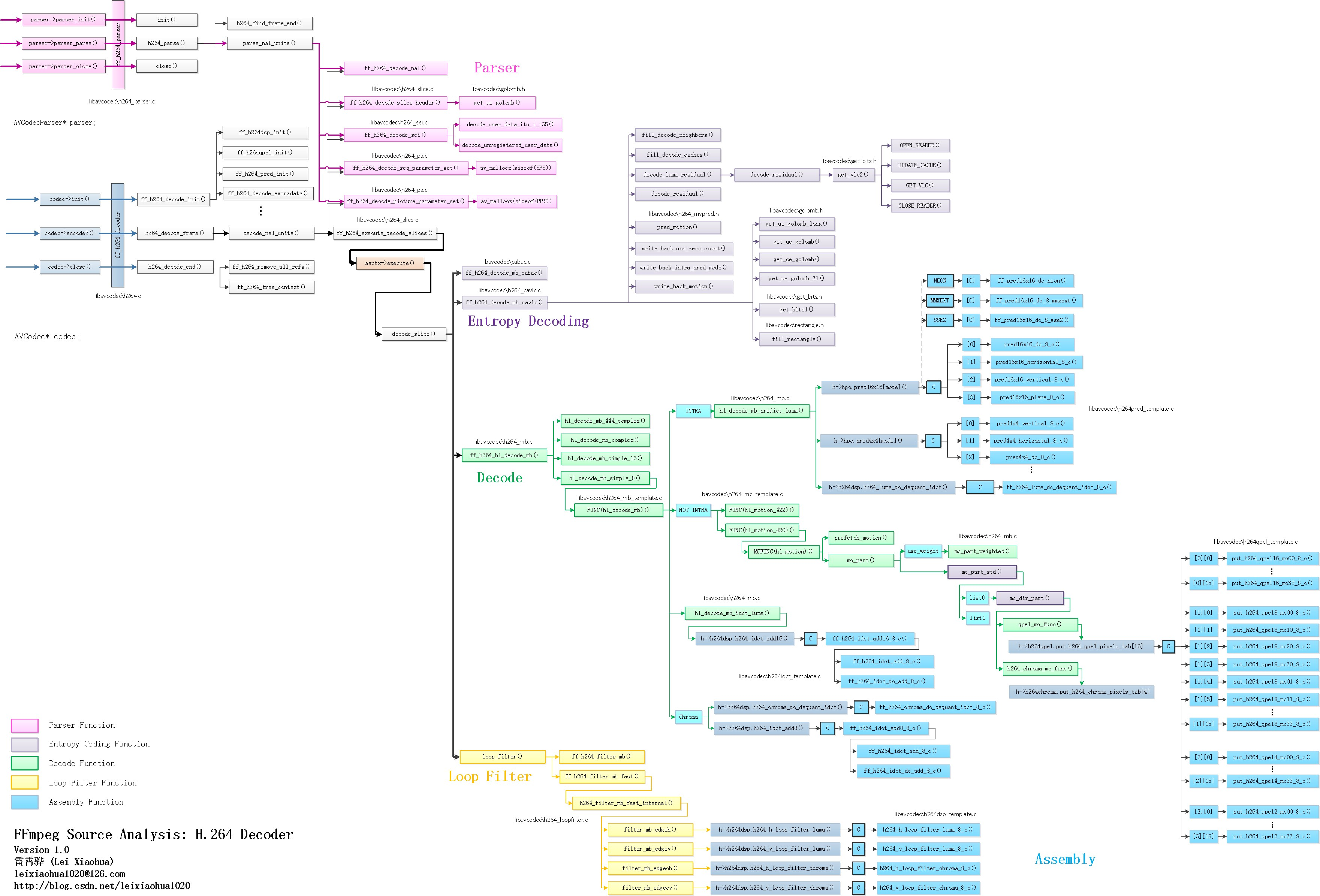
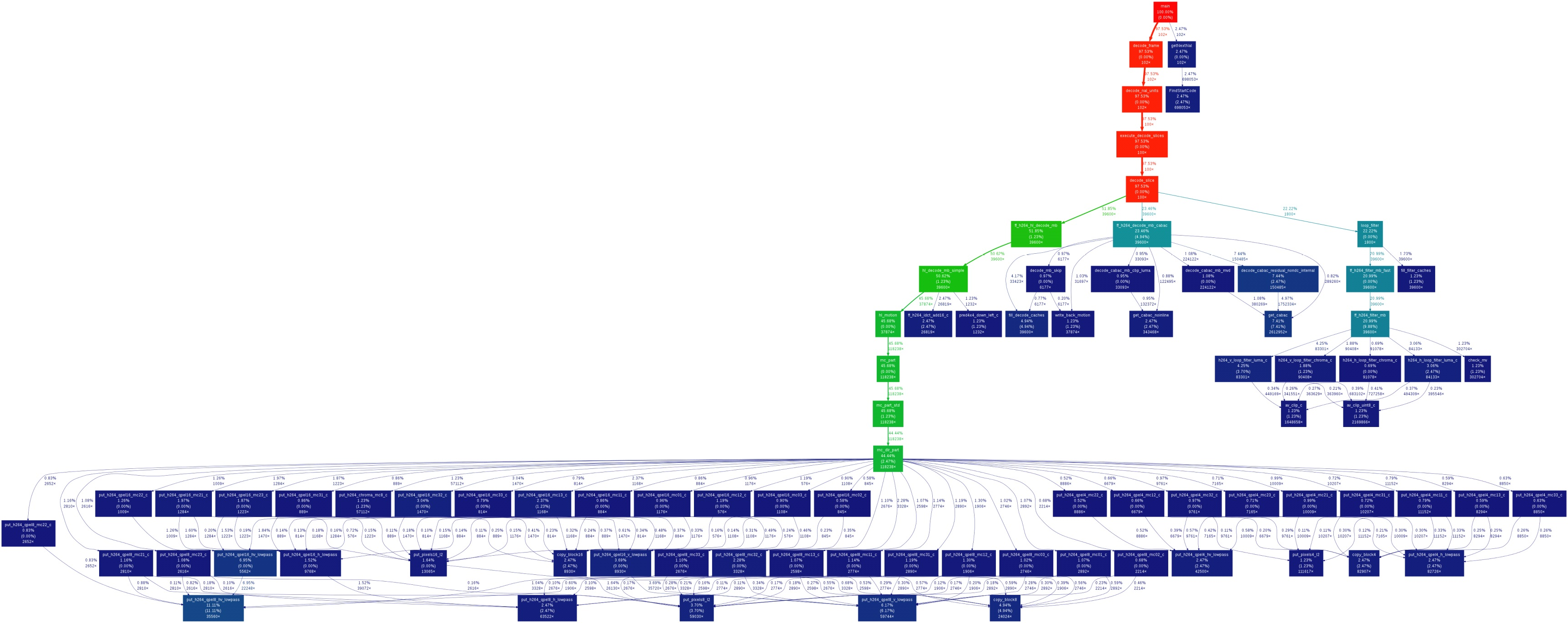
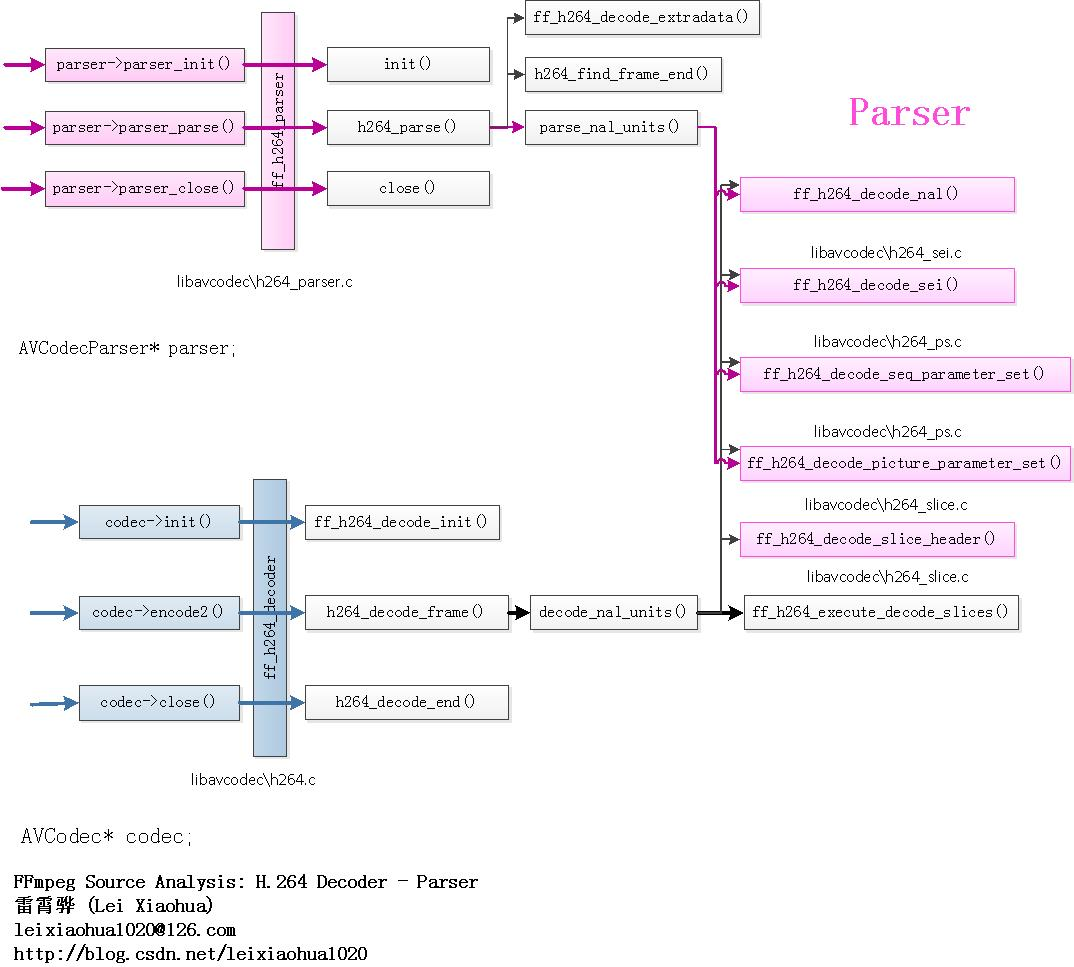
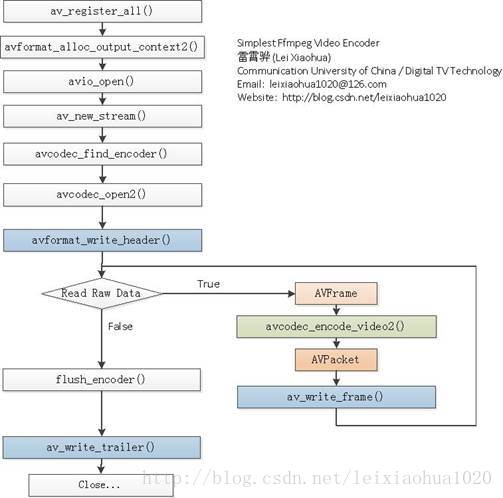
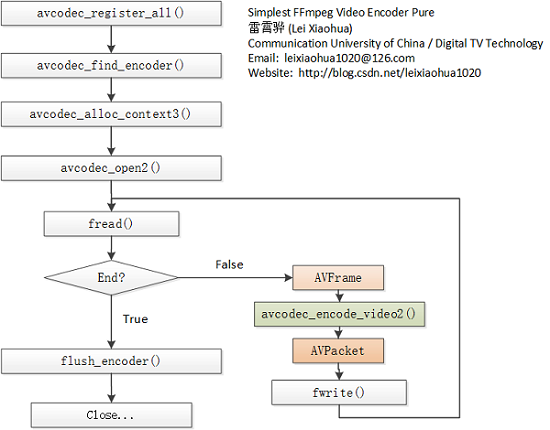
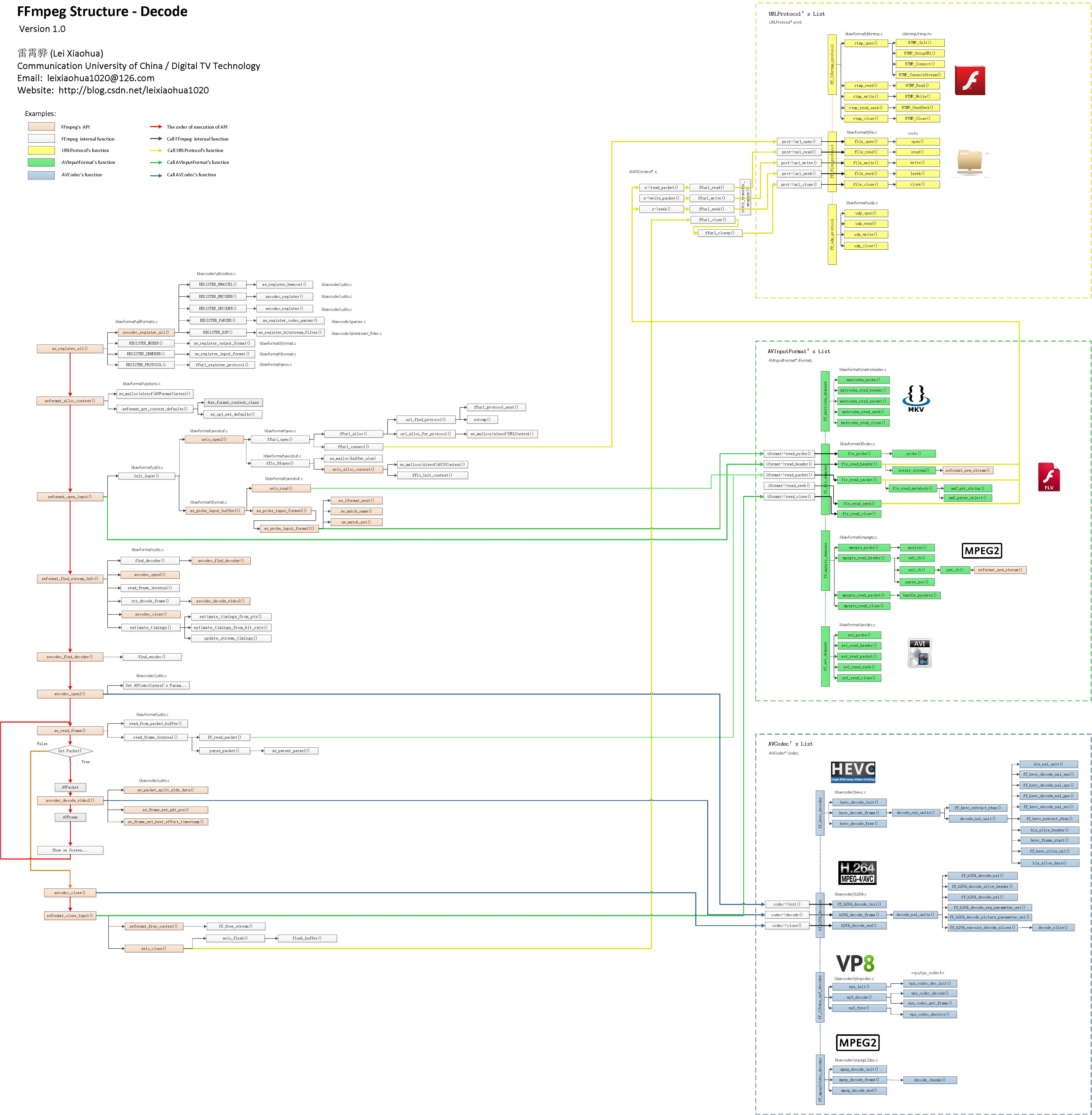
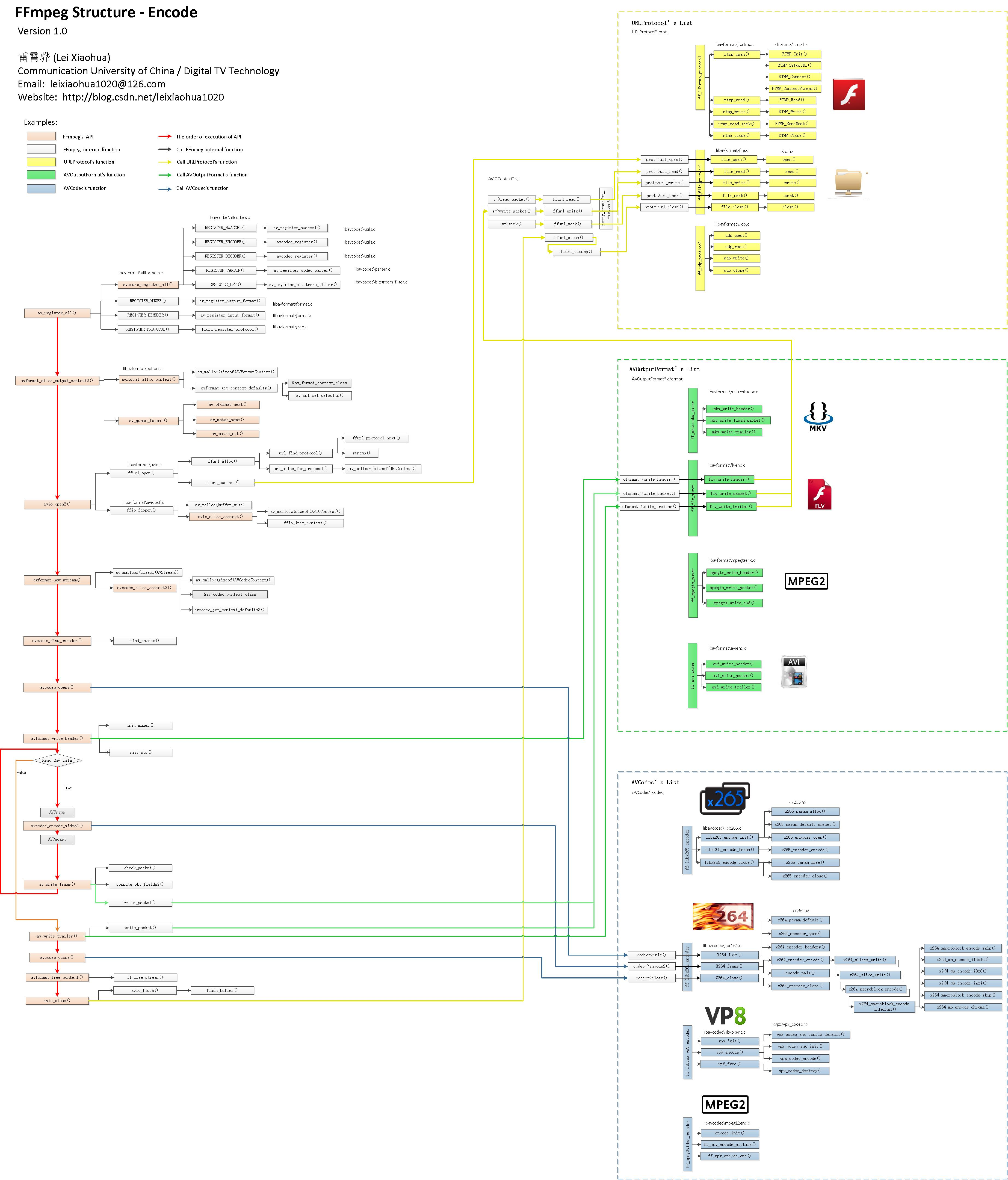
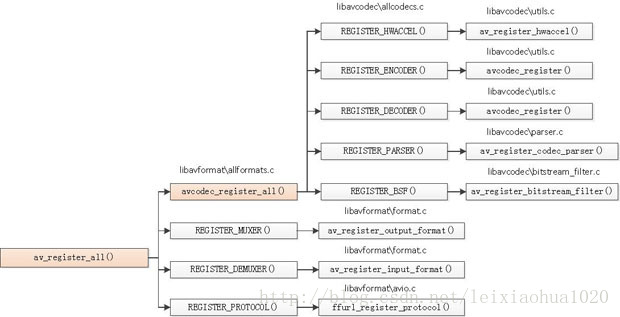
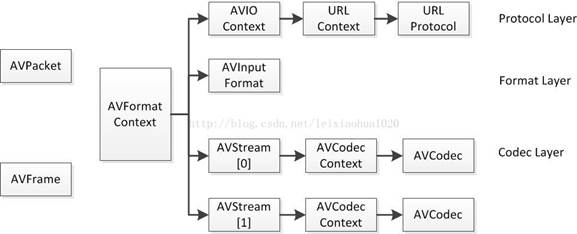
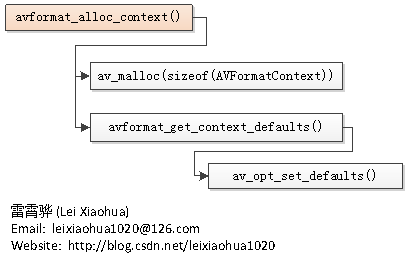
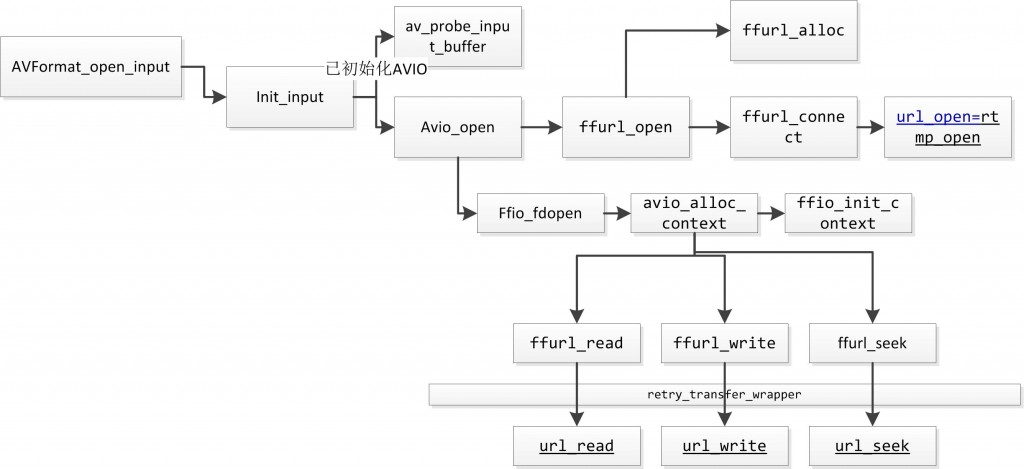
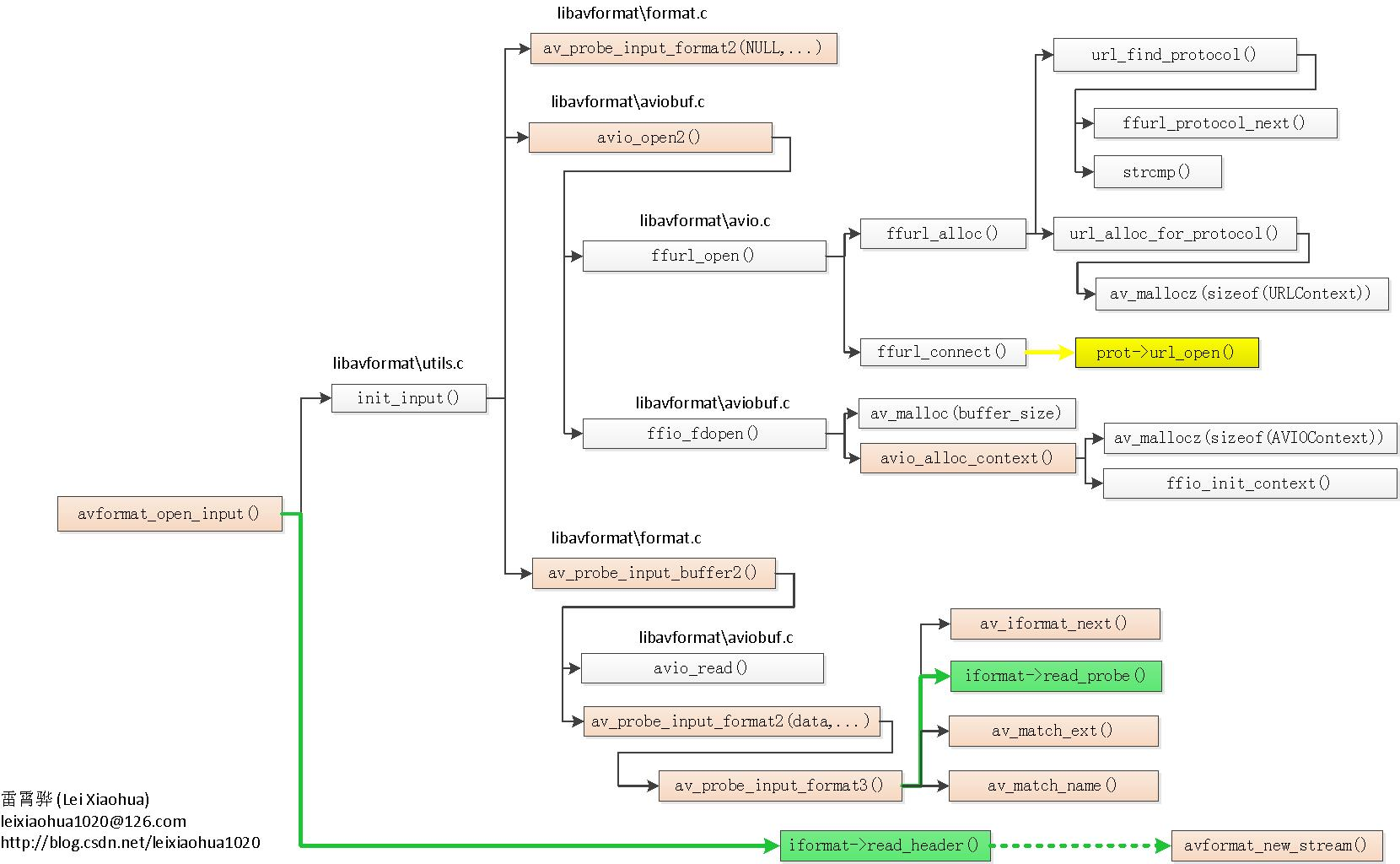
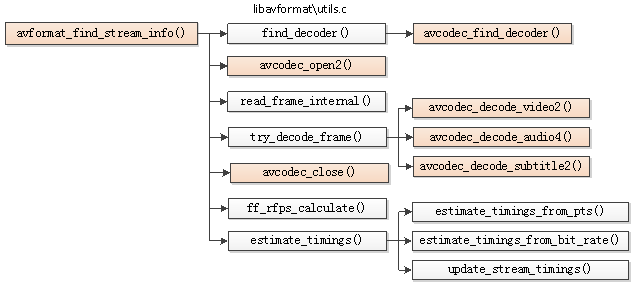
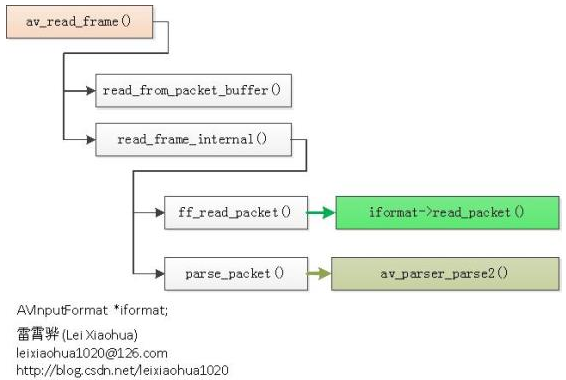
FFmpeg框架详解http://miaopei.github.io/2019/05/27/FFmpeg/FFmpeg框架函数分析/2019-05-27T02:14:50.000Z2019-07-01T06:23:39.119Z
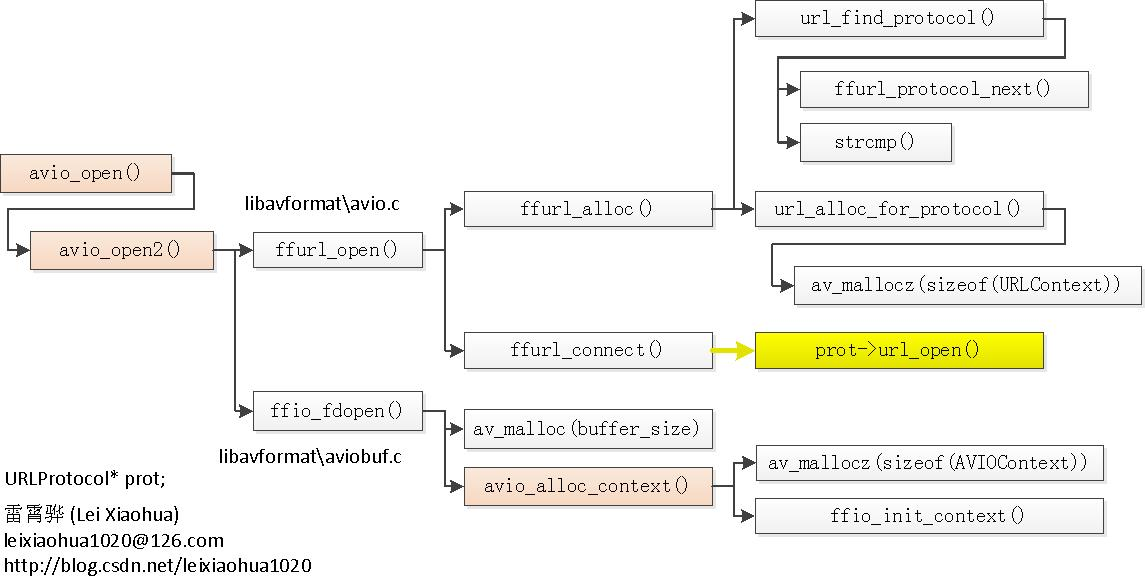
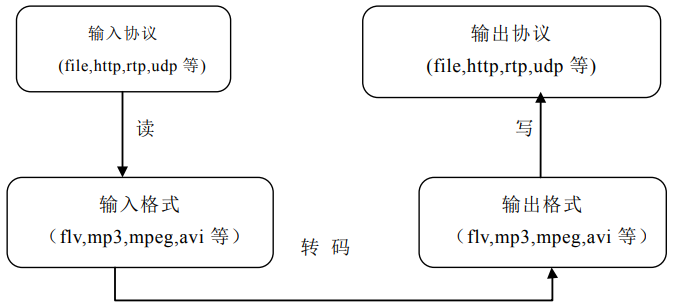
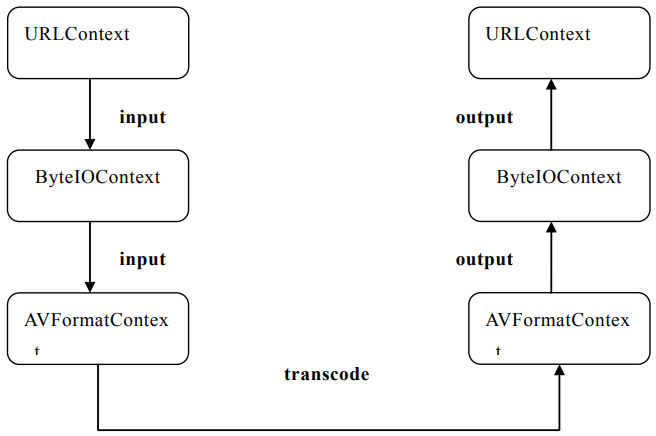
typedefstructURLProtocol { constchar *name; int (*url_open)(URLContext *h, constchar *url, int flags); int (*url_read)(URLContext *h, unsignedchar *buf, int size); int (*url_write)(URLContext *h, constunsignedchar *buf, int size); int64_t (*url_seek)(URLContext *h, int64_t pos, int whence); int (*url_close)(URLContext *h); structURLProtocol *next; int (*url_read_pause)(URLContext *h, int pause); int64_t (*url_read_seek)(URLContext *h, int stream_index, int64_t timestamp, int flags); int (*url_get_file_handle)(URLContext *h); int priv_data_size; const AVClass *priv_data_class; int flags; int (*url_check)(URLContext *h, int mask); } URLProtocol;
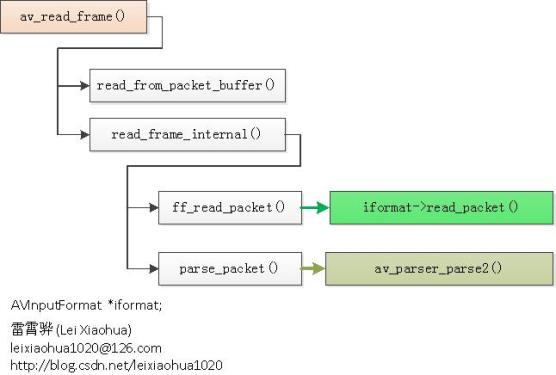
通过 av_read_packet(),读取一个包,需要说明的是此函数必须是包含整数帧的,不存在半帧的情况,以 ts 流为例,是读取一个完整的 PES 包(一个完整 pes 包包含若干视频或音频 es 包),读取完毕后,通过 av_parser_parse2() 分析出视频一帧(或音频若干帧),返回,下次进入循环的时候,如果上次的数据没有完全取完,则 st = s->cur_st ; 不会是 NULL,即再此进入 av_parser_parse2() 流程,而不是下面的 av_read_packet() 流程,这样就保证了,如果读取一次包含了 N 帧视频数据(以视频为例),则调用 av_read_frame() N 次都不会去读数据,而是返回第一次读取的数据,直到全部解析完毕。
1: keyframe (for AVC, a seekableframe)(关键帧) 2: inter frame (for AVC, a nonseekableframe) 3: disposable inter frame (H.263only) 4: generated keyframe (reservedfor server use only) 5: video info/command frame
第 1 个字节的后 4 位的数值表示视频编码 ID(CodecID):
1 2 3 4 5 6 7
1: JPEG (currently unused) 2: Sorenson H.263 3: Screen video 4: On2 VP6 5: On2 VP6 with alpha channel 6: Screen video version 2 7: AVC
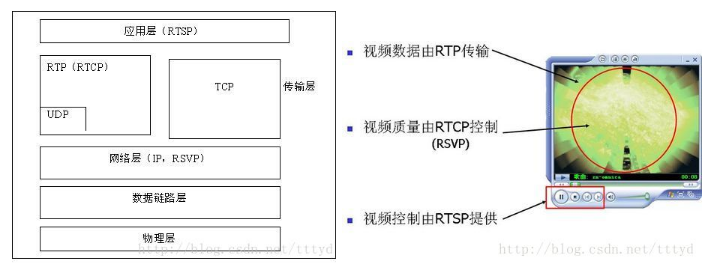
是由 Real Networks 和 Netscape 共同提出的。该协议定义了一对多应用程序如何有效地通过 IP 网络传送多媒体数据。RTSP 提供了一个可扩展框架,使实时数据,如音频与视频的受控、点播成为可能。数据源包括现场数据与存储在剪辑中的数据。该协议目的在于控制多个数据发送连接,为选择发送通道,如UDP、多播UDP与TCP提供途径,并为选择基于RTP上发送机制提供方法。
MMS (Microsoft Media Server Protocol),中文“微软媒体服务器协议”,用来访问并流式接收 Windows Media 服务器中 .asf 文件的一种协议。MMS 协议用于访问 Windows Media 发布点上的单播内容。MMS 是连接 Windows Media 单播服务的默认方法。若观众在 Windows Media Player 中键入一个 URL 以连接内容,而不是通过超级链接访问内容,则他们必须使用MMS 协议引用该流。MMS的预设埠(端口)是1755
如果连接到编入索引的 .asf 文件,想要快进、后退、暂停、开始和停止流,则必须使用 MMS。不能用 UNC 路径快进或后退。若您从独立的 Windows Media Player 连接到发布点,则必须指定单播内容的 URL。若内容在主发布点点播发布,则 URL 由服务器名和 .asf 文件名组成。例如:mms://windows_media_server/sample.asf。其中 windows_media_server 是 Windows Media 服务器名,sample.asf 是您想要使之转化为流的 .asf 文件名。
若您有实时内容要通过广播单播发布,则该 URL 由服务器名和发布点别名组成。例如:mms://windows_media_server/LiveEvents。这里 windows_media_server 是 Windows Media 服务器名,而 LiveEvents 是发布点名
HLS ( HTTP Live Streaming)苹果公司提出的流媒体协议,直接把流媒体切片成一段段,信息保存到m3u列表文件中,可以将不同速率的版本切成相应的片;播放器可以直接使用http协议请求流数据,可以在不同速率的版本间自由切换,实现无缝播放;省去使用其他协议的烦恼。缺点是延迟大小受切片大小影响,不适合直播,适合视频点播。
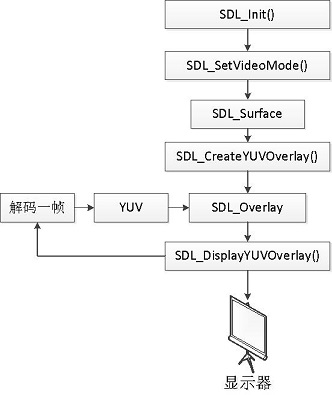
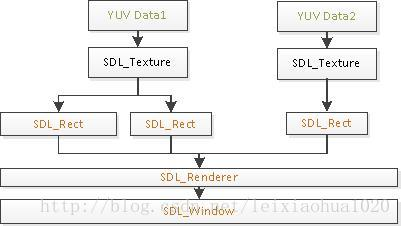
/** * 最简单的基于FFmpeg的视频播放器 2 * Simplest FFmpeg Player 2 * * 本程序实现了视频文件的解码和显示(支持HEVC,H.264,MPEG2等)。 * 是最简单的FFmpeg视频解码方面的教程。 * 通过学习本例子可以了解FFmpeg的解码流程。 * This software is a simplest video player based on FFmpeg. * Suitable for beginner of FFmpeg. * */
以 ts 流为例,是读取一个完整的 PES 包(一个完整 pes 包包含若干视频或音频 es 包),读取完毕后,通过 av_parser_parse2() 分析出视频一帧(或音频若干帧),返回,下次进入循环的时候,如果上次的数据没有完全取完,则 st = s->cur_st ; 不会是NULL,即再此进入 av_parser_parse2() 流程,而不是下面的 av_read_packet() 流程.
这样就保证了,如果读取一次包含了 N 帧视频数据(以视频为例),则调用 av_read_frame() N 次都不会去读数据,而是返回第一次读取的数据,直到全部解析完毕。
]]>
Welcome to my blog, enter password to read.
WebRTC(二)http://miaopei.github.io/2019/05/15/WebRTC/webrtc-02/2019-05-15T02:14:50.000Z2020-03-19T02:01:27.597Z
]]>
Welcome to my blog, enter password to read.
WebRTC(一)http://miaopei.github.io/2019/05/14/WebRTC/webrtc-01/2019-05-14T02:14:50.000Z2020-03-19T02:01:39.820Z
]]>
Welcome to my blog, enter password to read.
FFmpeg命令大全http://miaopei.github.io/2019/05/04/FFmpeg/FFmpeg命令大全/2019-05-04T02:14:50.000Z2019-06-05T04:03:57.388Z1. 前言
FFMPEG 是特别强大的专门用于处理音视频的开源库。你既可以使用它的 API 对音视频进行处理,也可以使用它提供的工具,如 ffmpeg, ffplay, ffprobe,来编辑你的音视频文件。
]]>
Welcome to my blog, enter password to read.
音视频入门知识http://miaopei.github.io/2019/04/23/FFmpeg/移动端音视频入门/2019-04-23T02:14:50.000Z2020-03-19T02:03:12.721Z
]]>
Welcome to my blog, enter password to read.
FFmpeg入门http://miaopei.github.io/2019/04/20/FFmpeg/FFmpeg入门/2019-04-20T02:14:50.000Z2019-07-01T07:37:16.507Z
typedefstructURLProtocol { constchar *name; int (*url_open)(URLContext *h, constchar *url, int flags); int (*url_read)(URLContext *h, unsignedchar *buf, int size); int (*url_write)(URLContext *h, constunsignedchar *buf, int size); int64_t (*url_seek)(URLContext *h, int64_t pos, int whence); int (*url_close)(URLContext *h); structURLProtocol *next; int (*url_read_pause)(URLContext *h, int pause); int64_t (*url_read_seek)(URLContext *h, int stream_index, int64_t timestamp, int flags); int (*url_get_file_handle)(URLContext *h); int priv_data_size; const AVClass *priv_data_class; int flags; int (*url_check)(URLContext *h, int mask); } URLProtocol;
typedefstructURLContext { const AVClass *av_class; ///< information for av_log(). Set by url_open(). structURLProtocol *prot; int flags; int is_streamed; /**< true if streamed (no seek possible), default = false */ int max_packet_size; void *priv_data; char *filename; /**< specified URL */ int is_connected; } URLContext;
typedefstruct { unsignedchar *buffer; /**< Start of the buffer. */ int buffer_size; /**< Maximum buffer size */ unsignedchar *buf_ptr; /**< Current position in the buffer */ unsignedchar *buf_end; void *opaque; //关联 URLContext int (*read_packet)(void *opaque, uint8_t *buf, int buf_size); int (*write_packet)(void *opaque, uint8_t *buf, int buf_size); int64_t (*seek)(void *opaque, int64_t offset, int whence); int64_t pos; int must_flush; int eof_reached; /**< true if eof reached */ int write_flag; /**< true if open for writing */ int max_packet_size; unsignedlong checksum; unsignedchar *checksum_ptr; unsignedlong(*update_checksum)(unsignedlong checksum, constuint8_t *buf, unsignedint size); int error; int (*read_pause)(void *opaque, int pause); int64_t (*read_seek)(void *opaque, int stream_index,int64_t timestamp,int flags); int seekable; } AVIOContext;
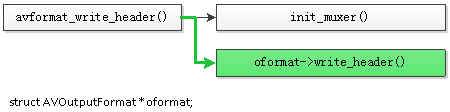
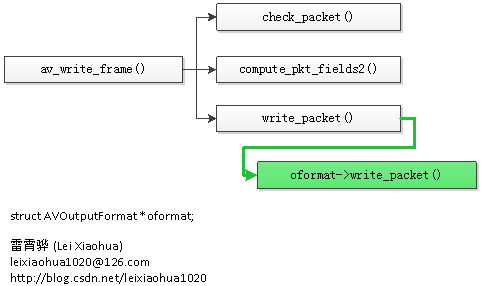
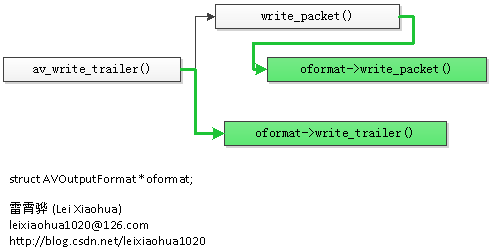
int (*write_header)(struct AVFormatContext *); int (*write_packet)(struct AVFormatContext *, AVPacket *pkt); int (*write_trailer)(struct AVFormatContext *);
typedefstructAVPacket { int64_t pts; ///< presentation time stamp in time_base units int64_t dts; ///< decompression time stamp in time_base units uint8_t *data; int size; int stream_index; int flags; int duration; ///< presentation duration in time_base units void (*destruct)(struct AVPacket *); void *priv; int64_t pos; ///< byte position in stream, -1 if unknown } AVPacket;
当 configure 进行他的测试时,会输出简要的信息来告诉用户正在作什么。这样做是因为 configure 可能会比较慢,没有这种输出的话用户将会被扔在一旁疑惑正在发生什么。使用这两个选项中的任何一个都会把你扔到一旁。(译注:这两句话比较有意思,原文是这样的:If there was no such output, the user would be left wondering what is happening. By using this option, you too can be left wondering!)
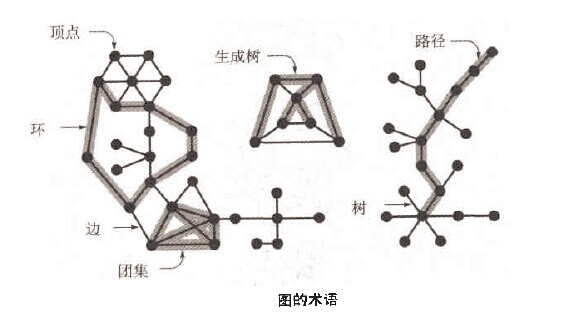
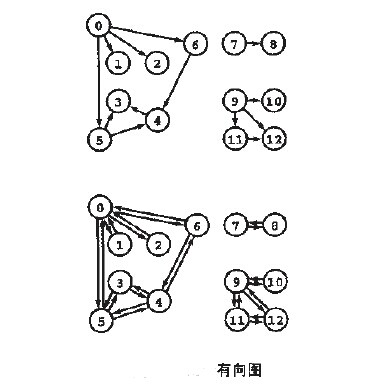
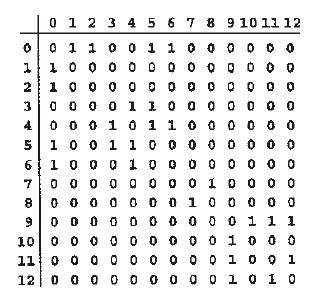
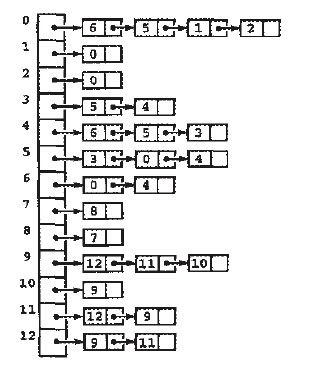
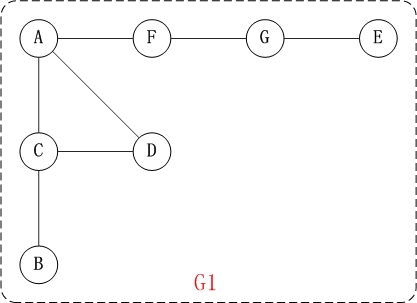
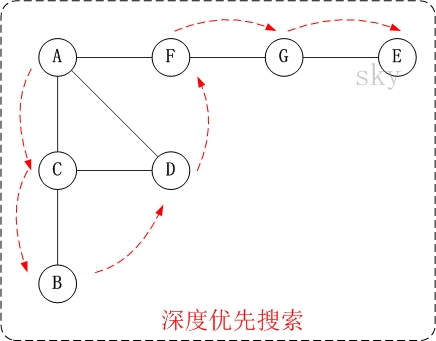
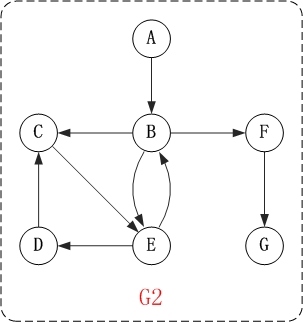
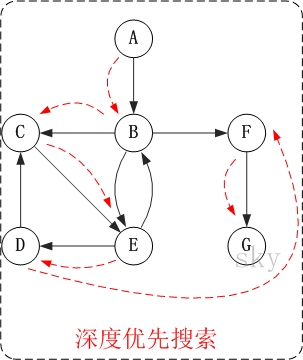
/* * 深度优先搜索遍历图 */ void ListUDG::DFS() { int i; int visited[MAX]; // 顶点访问标记
// 初始化所有顶点都没有被访问 for (i = 0; i < mVexNum; i++) visited[i] = 0;
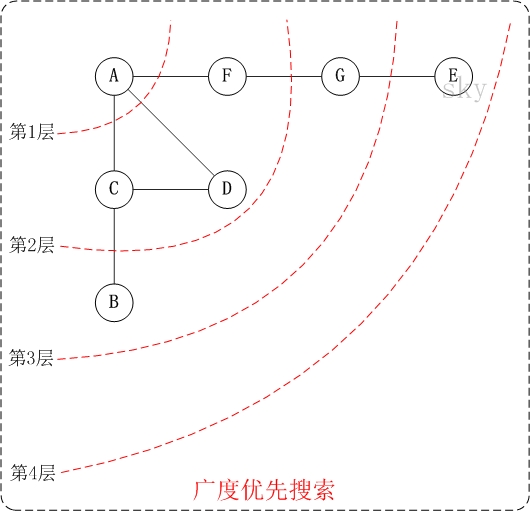
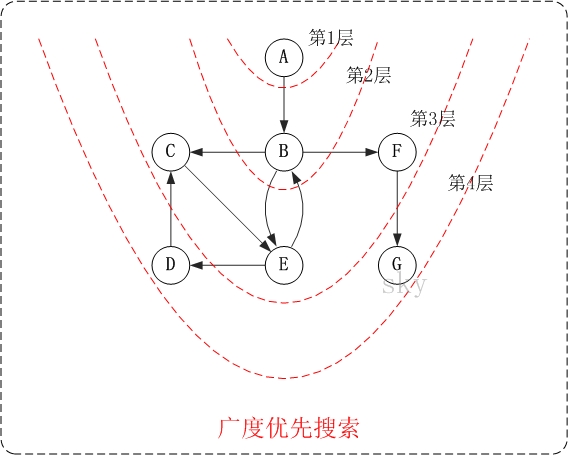
cout << "DFS: "; for (i = 0; i < mVexNum; i++) { if (!visited[i]) DFS(i, visited); } cout << endl; } /* * 广度优先搜索(类似于树的层次遍历) */ void ListUDG::BFS() { int head = 0; int rear = 0; intqueue[MAX]; // 辅组队列 int visited[MAX]; // 顶点访问标记 int i, j, k; ENode *node;
for (i = 0; i < mVexNum; i++) visited[i] = 0;
cout << "BFS: "; for (i = 0; i < mVexNum; i++) { if (!visited[i]) { visited[i] = 1; cout << mVexs[i].data << " "; queue[rear++] = i; // 入队列 } while (head != rear) { j = queue[head++]; // 出队列 node = mVexs[j].firstEdge; while (node != NULL) { k = node->ivex; if (!visited[k]) { visited[k] = 1; cout << mVexs[k].data << " "; queue[rear++] = k; } node = node->nextEdge; } } } cout << endl; }
此外,如果你的 Mac 安装了zsh(参考《全新Mac安装指南(编程篇),那么可以直接使用 gst、glog 等一系列快捷命令,详情见此列表:Plugin:git 。
问:git submodule update 时出错怎么解决?
例如,在执行 git submodule update 时有以下错误信息:
fatal: reference is not a tree: f869da471c5d8a185cd110bbe4842d6757b002f5 Unable to checkout ‘f869da471c5d8a185cd110bbe4842d6757b002f5’ in submodule path ‘source/i18n-php-server’
switch (ws.readyState) { case WebSocket.CONNECTING: // do something break; case WebSocket.OPEN: // do something break; case WebSocket.CLOSING: // do something break; case WebSocket.CLOSED: // do something break; default: // this never happens break; }
webSocket.onopen
实例对象的 onopen 属性,用于指定连接成功后的回调函数。
1 2 3
ws.onopen = function () { ws.send('Hello Server!'); }
如果要指定多个回调函数,可以使用addEventListener`方法。
1 2 3
ws.addEventListener('open', function (event) { ws.send('Hello Server!'); });
webSocket.onclose
实例对象的onclose属性,用于指定连接关闭后的回调函数。
1 2 3 4 5 6 7 8 9 10 11 12 13
ws.onclose = function(event) { var code = event.code; var reason = event.reason; var wasClean = event.wasClean; // handle close event };
ws.addEventListener("close", function(event) { var code = event.code; var reason = event.reason; var wasClean = event.wasClean; // handle close event });
webSocket.onmessage
实例对象的 onmessage 属性,用于指定收到服务器数据后的回调函数。
1 2 3 4 5 6 7 8 9
ws.onmessage = function(event) { var data = event.data; // 处理数据 };
ws.addEventListener("message", function(event) { var data = event.data; // 处理数据 });
常用于算术运算比较,双括号中的变量可以不使用$ 符号前缀。括号内支持多个表达式用逗号分开。 只要括号中的表达式符合C语言运算规则,比如可以直接使用for((i=0;i<5;i++)), 如果不使用双括号, 则为for i in seq 0 4或者for i in {0..4}。再如可以直接使用 if (($i<5)) , 如果不使用双括号, 则为 if [ $i -lt 5 ] 。
Test和[]中可用的比较运算符只有==和!=,两者都是用于字符串比较的,不可用于整数比较,整数比较只能使用-eq,-gt这种形式。无论是字符串比较还是整数比较都不支持大于号小于号。如果实在想用,对于字符串比较可以使用转义形式,如果比较”ab”和”bc”:[ ab < bc ],结果为真,也就是返回状态为0。[ ]中的逻辑与和逻辑或使用-a 和-o 表示。
回车键 # 向下移动一行; y # 向上移动一行; 空格键 # 向下滚动一屏; b # 向上滚动一屏; d # 向下滚动半屏; h # less的帮助; u # 向上洋动半屏; w # 可以指定显示哪行开始显示,是从指定数字的下一行显示;比如指定的是6,那就从第7行显示; g # 跳到第一行; G # 跳到最后一行; p # n% 跳到n%,比如 10%,也就是说比整个文件内容的10%处开始显示; /pattern # 搜索pattern ,比如 /MAIL表示在文件中搜索MAIL单词; v # 调用vi编辑器; q # 退出less !command# 调用SHELL,可以运行命令;比如!ls 显示当前列当前目录下的所有文件;
# A small example program for using the new getopt(1) program. # This program will only work with bash(1) # An similar program using the tcsh(1) script. language can be found # as parse.tcsh
# Example input and output (from the bash prompt): # ./parse.bash -a par1 'another arg' --c-long 'wow!*\?' -cmore -b " very long " # Option a # Option c, no argument # Option c, argument `more' # Option b, argument ` very long ' # Remaining arguments: # --> `par1' # --> `another arg' # --> `wow!*\?' # Note that we use `"$@"' to let each command-line parameter expand to a # separate word. The quotes around `$@' are essential! # We need TEMP as the `evalset --' would nuke the return value of getopt. #-o表示短选项,两个冒号表示该选项有一个可选参数,可选参数必须紧贴选项 #如-carg 而不能是-c arg #--long表示长选项 #"$@"在上面解释过 # -n:出错时的信息 # -- :举一个例子比较好理解: #我们要创建一个名字为 "-f"的目录你会怎么办? # mkdir -f #不成功,因为-f会被mkdir当作选项来解析,这时就可以使用 # mkdir -- -f 这样-f就不会被作为选项。 TEMP=`getopt -o ab:c:: --long a-long,b-long:,c-long:: \ -n 'example.bash' -- "$@"` if [ $? != 0 ] ; then echo "Terminating..." >&2 ; exit 1 ; fi # Note the quotes around `$TEMP': they are essential! #set 会重新排列参数的顺序,也就是改变$1,$2...$n的值,这些值在getopt中重新排列过了 evalset -- "$TEMP"
#经过getopt的处理,下面处理具体选项。
whiletrue ; do case"$1"in -a|--a-long) echo "Option a" ; shift ;; -b|--b-long) echo "Option b, argument \`$2'" ; shift 2 ;; -c|--c-long) # c has an optional argument. As we are in quoted mode, # an empty parameter will be generated if its optional # argument is not found. case"$2"in "") echo "Option c, no argument"; shift 2 ;; *) echo "Option c, argument \`$2'" ; shift 2 ;; esac ;; --) shift ; break ;; *) echo "Internal error!" ; exit 1 ;; esac done echo "Remaining arguments:" for arg do echo '--> '"\`$arg'" ; done
a\ # 在当前行下面插入文本。 i\ # 在当前行上面插入文本。 c\ # 把选定的行改为新的文本。 d # 删除,删除选择的行。 D # 删除模板块的第一行。 s # 替换指定字符 h 拷贝模板块的内容到内存中的缓冲区。 H # 追加模板块的内容到内存中的缓冲区。 g # 获得内存缓冲区的内容,并替代当前模板块中的文本。 G # 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l # 列表不能打印字符的清单。 n # 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N # 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p # 打印模板块的行。 P(大写) 打印模板块的第一行。 q # 退出Sed。 b lable # 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 r file # 从file中读行。 t label # if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label # 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file # 写并追加模板块到file末尾。 W file # 写并追加模板块的第一行到file末尾。 ! # 表示后面的命令对所有没有被选定的行发生作用。 = # 打印当前行号码。 # 把注释扩展到下一个换行符以前。
sed 替换标记:
1 2 3 4 5 6 7
g # 表示行内全面替换。 p # 表示打印行。 w # 表示把行写入一个文件。 x # 表示互换模板块中的文本和缓冲区中的文本。 y # 表示把一个字符翻译为另外的字符(但是不用于正则表达式) \1 # 子串匹配标记 & # 已匹配字符串标记
# sed可以替换给定文本中的字符串。 $ sed 's/pattern/replace_string/' file
# 如果需要在替换的同时保存更改,可以使用-i选项 $ sed -i 's/text/replace/' file
# 后缀/g意味着sed会替换每一处匹配。但是有时候我们只需要从第n处匹配开始替换。对此,可以使用/Ng选项。 $ sed 's/pattern/replace_string/g' file $ echo thisthisthisthis | sed 's/this/THIS/2g' thisTHISTHISTHIS $ echo thisthisthisthis | sed 's/this/THIS/3g' thisthisTHISTHIS
# 字符/在sed中被作为定界符使用。我们可以像下面一样使用任意的定界符: $ sed 's:text:replace:g' $ sed 's|text|replace|g' # 当定界符出现在样式内部时,我们必须用前缀\对它进行转义: $ sed 's|te\|xt|replace|g' # \|是一个出现在样式内部并经过转义的定界符。
# 移除空白行 $ sed '/^$/d' file
# 已匹配字符串标记(&)在sed中,我们可以用 &标记匹配样式的字符串,这样就能够在替换字符串时使用已匹配的内容。 $ echo this is an example | sed 's/\w\+/[&]/g' [this] [is] [an] [example] # 正则表达式 \w\+ 匹配每一个单词,然后我们用[&]替换它。 & 对应于之前所匹配到的单词。
# 组合多个表达式 $ sed 'expression' | sed 'expression' # 它等价于 $ sed 'expression; expression' # 或者 $ sed -e 'expression' -e expression' # 引用。sed表达式通常用单引号来引用。双引号会通过对表达式求值来对其进行扩展。 $ text=hello $ echo hello world | sed "s/$text/HELLO/" HELLO world
4.5 awk 进行高级文本处理
4.5.1 awk 常用命令选项
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf 选项限制分配给val的最大块数目;-mr 选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
$ echo -e "line1 f2 f3nline2 f4 f5nline3 f6 f7" | awk '{print "Line No:"NR", No of fields:"NF, "$0="$0, "$1="$1, "$2="$2, "$3="$3}' Line No:1, No of fields:3 $0=line1 f2 f3 $1=line1 $2=f2 $3=f3 Line No:2, No of fields:3 $0=line2 f4 f5 $1=line2 $2=f4 $3=f5 Line No:3, No of fields:3 $0=line3 f6 f7 $1=line3 $2=f6 $3=f7
$ cat text.txt web01[192.168.2.100] httpd ok tomcat ok sendmail ok web02[192.168.2.101] httpd ok postfix ok web03[192.168.2.102] mysqld ok httpd ok 0
$ awk '/^web/{T=$0;next;}{print T":t"$0;}' test.txt web01[192.168.2.100]: httpd ok web01[192.168.2.100]: tomcat ok web01[192.168.2.100]: sendmail ok web02[192.168.2.101]: httpd ok web02[192.168.2.101]: postfix ok web03[192.168.2.102]: mysqld ok web03[192.168.2.102]: httpd ok
# 得到数组长度 $ awk 'BEGIN{info="it is a test";lens=split(info,tA," ");print length(tA),lens;}' 4 4 # length返回字符串以及数组长度,split进行分割字符串为数组,也会返回分割得到数组长度。
# asort对数组进行排序,返回数组长度。 $ awk 'BEGIN{info="it is a test";split(info,tA," ");print asort(tA);}' 4
# 输出数组内容(无序,有序输出): $ awk 'BEGIN{info="it is a test";split(info,tA," ");for(k in tA){print k,tA[k];}}' 4 test 1 it 2 is 3 a
# for…in 输出,因为数组是关联数组,默认是无序的。所以通过 for…in 得到是无序的数组。如果需要得到有序数组,需要通过下标获得。 $ awk 'BEGIN{info="it is a test";tlen=split(info,tA," ");for(k=1;k<=tlen;k++){print k,tA[k];}}' 1 it 2 is 3 a 4 test # 注意:数组下标是从1开始,与C数组不一样。
# 判断键值存在以及删除键值: $ awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";if( "c" in tB){print "ok";};for(k in tB){print k,tB[k];}}' a a1 b b1 # 删除键值: $ awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";delete tB["a"];for(k in tB){print k,tB[k];}}' b b1
用 Repl 参数指定的字符串替换 In 参数指定的字符串中的由 Ere 参数指定的扩展正则表达式的第一个具体值。sub 函数返回替换的数量。出现在 Repl 参数指定的字符串中的 &(和符号)由 In 参数指定的与 Ere 参数的指定的扩展正则表达式匹配的字符串替换。如果未指定 In 参数,缺省值是整个记录($0 记录变量)
将 String 参数指定的参数分割为数组元素 A[1], A[2], . . ., A[n],并返回 n 变量的值。此分隔可以通过 Ere 参数指定的扩展正则表达式进行,或用当前字段分隔符(FS 特殊变量)来进行(如果没有给出 Ere 参数)。除非上下文指明特定的元素还应具有一个数字值,否则 A 数组中的元素用字符串值来创建
Spider mode enabled. Check if remote file exists. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Remote file exists and could contain further links, but recursion is disabled -- not retrieving.
这保证了下载能在预定的时间进行,但当你给错了一个链接,将会显示如下错误:
1 2 3 4
$ wget --spider url Spider mode enabled. Check if remote file exists. HTTP request sent, awaiting response... 404 Not Found Remote file does not exist -- broken link!!!
# DNS查找 $ host google.com google.com has address 64.233.181.105 google.com has address 64.233.181.99 google.com has address 64.233.181.147 google.com has address 64.233.181.106 google.com has address 64.233.181.103 google.com has address 64.233.181.104
$ traceroute google.com traceroute to google.com (74.125.77.104), 30 hops max, 60 byte packets 1 gw-c6509.lxb.as5577.net (195.26.4.1) 0.313 ms 0.371 ms 0.457 ms 2 40g.lxb-fra.as5577.net (83.243.12.2) 4.684 ms 4.754 ms 4.823 ms 3 de-cix10.net.google.com (80.81.192.108) 5.312 ms 5.348 ms 5.327 ms 4 209.85.255.170 (209.85.255.170) 5.816 ms 5.791 ms 209.85.255.172 (209.85.255.172) 5.678 ms 5 209.85.250.140 (209.85.250.140) 10.126 ms 9.867 ms 10.754 ms 6 64.233.175.246 (64.233.175.246) 12.940 ms 72.14.233.114 (72.14.233.114) 13.736 ms 13.803 ms 7 72.14.239.199 (72.14.239.199) 14.618 ms 209.85.255.166 (209.85.255.166) 12.755 ms 209.85.255.143 (209.85.255.143) 13.803 ms 8 209.85.255.98 (209.85.255.98) 22.625 ms 209.85.255.110 (209.85.255.110) 14.122 ms * 9 ew-in-f104.1e100.net (74.125.77.104) 13.061 ms 13.256 ms 13.484 ms
7.3 列出网络上所有的活动主机 (fping)
fping的选项如下:
选项 -a指定打印出所有活动主机的IP地址;
选项 -u指定打印出所有无法到达的主机;
选项 -g指定从 “IP地址/子网掩码”记法或者”IP地址范围”记法中生成一组IP地址;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ fping -a 192.160.1/24 -g # 或者 $ fping -a 192.160.1 192.168.0.255 -g
# 我们可以用已有的命令行工具来查询网络上的主机状态: $ fping -a 192.160.1/24 -g 2> /dev/null 192.168.0.1 192.168.0.90 # 或者,使用: $ fping -a 192.168.0.1 192.168.0.255 -g
# >/dev/null将由于主机无法到达所产生的错误信息打印到null设备。 $ fping -a 192.168.0.1 192.168.0.5 192.168.0.6 # 将IP地址作为参数传递 $ fping -a < ip.list # 从文件中传递一组IP地址
# 向系统日志文件/var/log/message中写入日志信息: $ logger This is a testlog line $ tail -n 1 /var/log/messages Sep 29 07:47:44 slynux-laptop slynux: This is a testlog line # 如果要记录特定的标记(tag),可以使用: $ logger -t TAG This is a message $ tail -n 1 /var/log/messages Sep 29 07:48:42 slynux-laptop TAG: This is a message # 但是当logger发送消息时,它用标记字符串来确定应该记录到哪一个日志文件中。 syslogd使用与日志相关联的TAG来决定应该将其记录到哪一个文件中。你可以从/etc/rsyslog.d/目录下的配置文件中看到标记字符串以及与其相关联的日志文件。
# 捕捉并响应信号 # trap命令在脚本中用来为信号分配信号处理程序。 $ trap'signal_handler_function_name' SIGNAL LIST
9.4 向用户终端发送消息
1 2 3 4 5 6 7
# wall命令用来向当前所有登录用户的终端写入消息。 $ cat message | wall 或者 $ wall< message Broadcast Message from slynux@slynux-laptop (/dev/pts/1) at 12:54 ... This is a messag
// The Vue build version to load with the `import` command // (runtime-only or standalone) has been set in webpack.base.conf with an alias. import Vue from'vue' import App from'./App' import router from'./router'
8) CGI 程序需要通过管道(pipe)方式与 Web Server 通信,而 FastCGI 则是通过 Unix-Domain-Sockets 或 TCP/IP 方式来实现与 Web Server 的通信。这确保了 FastCGI 可以运行在 Web Server 之外的服务器上。FastCGI 提供了 FastCGI 负载均衡器,它可以有效控制多个独立的 FastCGI Server 的负载,这种方式比 load-balancer+apache+mod_php 方式能够承担更多的流量。
$HTTP["scheme"] == "http" { # capture vhost name with regex conditiona -> %0 in redirect pattern # must be the most inner block to the redirect rule $HTTP["host"] =~ ".*" { url.redirect = (".*" => "https://%0$0") } }
# Site title:Hexo#网站标题 subtitle:#网站副标题 description:#网站描述 author:JohnDoe#作者 language:#语言 timezone:#网站时区。Hexo 默认使用您电脑的时区。时区列表。比如说:America/New_York, Japan, 和 UTC 。
# URL ## If your site is put in a subdirectory, set url as 'http://yoursite.com/child' and root as '/child/' url:http://yoursite.com#你的站点Url root:/#站点的根目录 permalink::year/:month/:day/:title/#文章的 永久链接 格式 permalink_defaults:#永久链接中各部分的默认值
# Category & Tag default_category:uncategorized category_map:#分类别名 tag_map:#标签别名
# Date / Time format ## Hexo uses Moment.js to parse and display date ## You can customize the date format as defined in ## http://momentjs.com/docs/#/displaying/format/ date_format:YYYY-MM-DD#日期格式 time_format:HH:mm:ss#时间格式
# Pagination ## Set per_page to 0 to disable pagination per_page:10#分页数量 pagination_dir:page
Present-tense summary under 50 characters* More information about commit (under 72 characters).* More information about commit (under 72 characters).http://project.management-system.com/ticket/123
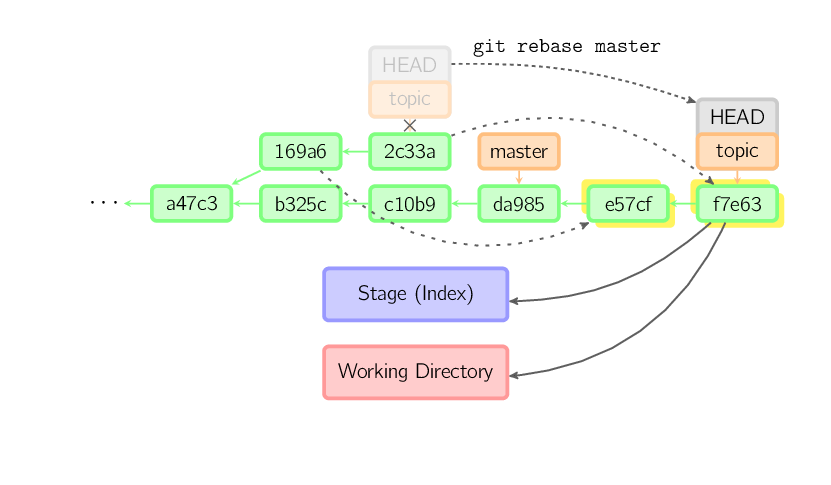
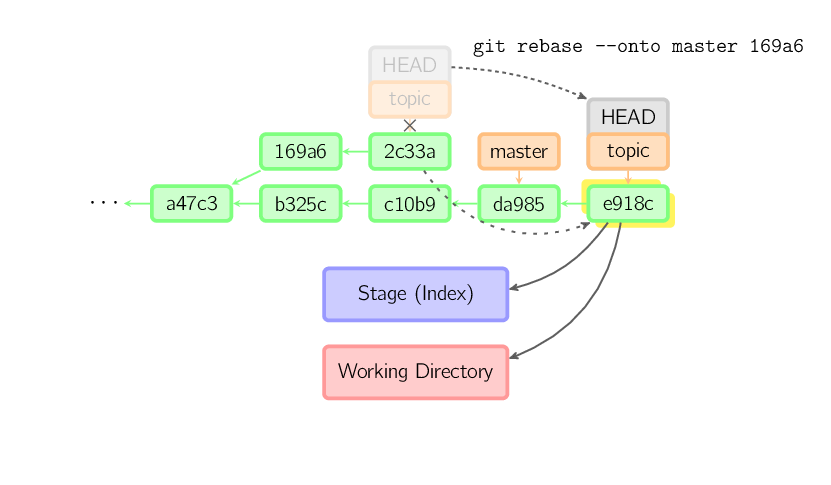
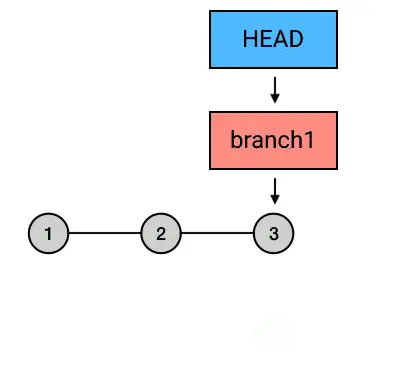
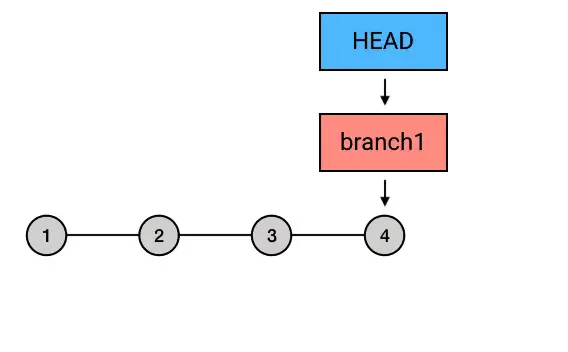
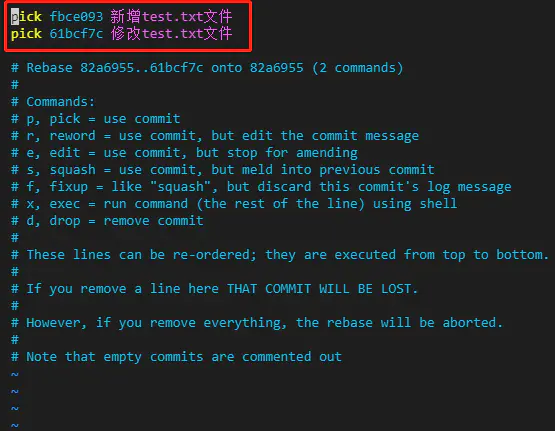
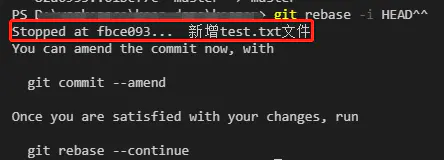
git rebase 命令的 i 参数表示互动(interactive),这时git会打开一个互动界面,进行下一步操作。
pick 07c5abd Introduce OpenPGP and teach basic usagepick de9b1eb Fix PostChecker::Post#urlspick 3e7ee36 Hey kids, stop all the highlightingpick fa20af3 git interactive rebase, squash, amend# Rebase 8db7e8b..fa20af3 onto 8db7e8b## Commands:# p, pick = use commit# r, reword = use commit, but edit the commit message# e, edit = use commit, but stop for amending# s, squash = use commit, but meld into previous commit# f, fixup = like "squash", but discard this commit's log message# x, exec = run command (the rest of the line) using shell## These lines can be re-ordered; they are executed from top to bottom.## If you remove a line here THAT COMMIT WILL BE LOST.## However, if you remove everything, the rebase will be aborted.## Note that empty commits are commented out
上面的互动界面,先列出当前分支最新的4个 commit(越下面越新)。每个 commit 前面有一个操作命令,默认是 pick,表示该行 commit 被选中,要进行 rebase 操作。
# This is a combination of 3 commits.# The first commit's message is:Introduce OpenPGP and teach basic usage# This is the 2nd commit message:Fix PostChecker::Post#urls# This is the 3rd commit message:Hey kids, stop all the highlighting
如果将第三行的 squash 命令改成 fixup 命令。
pick 07c5abd Introduce OpenPGP and teach basic usages de9b1eb Fix PostChecker::Post#urlsf 3e7ee36 Hey kids, stop all the highlightingpick fa20af3 git interactive rebase, squash, amend
# This is a combination of 3 commits.# The first commit's message is:Introduce OpenPGP and teach basic usage# This is the 2nd commit message:Fix PostChecker::Post#urls# This is the 3rd commit message:# Hey kids, stop all the highlighting
# Vsersion: 0.0.1 FROM ubuntu:16.04 MAINTAINER Micheal "miaopei@baicells.com" RUN apt-get -yqq update && apt-get -y install nginx RUN echo 'Hi, I an in your container' > /usr/share/nginx/html/index.html EXPOSE 80
建筑商从来不会去想给一栋已建好的100层高的楼房底下再新修一个小地下室——这样做花费极大而且注定要失败。然而令人惊奇的是,软件系统的用户在要求作出类似改变时却不会仔细考虑,而且他们认为这只是需要简单编程的事。 ——Object-Oriented Analysis and Design with Applications
SkipList是由William Pugh发明。他在Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了SkipList的数据结构和插入删除操作。
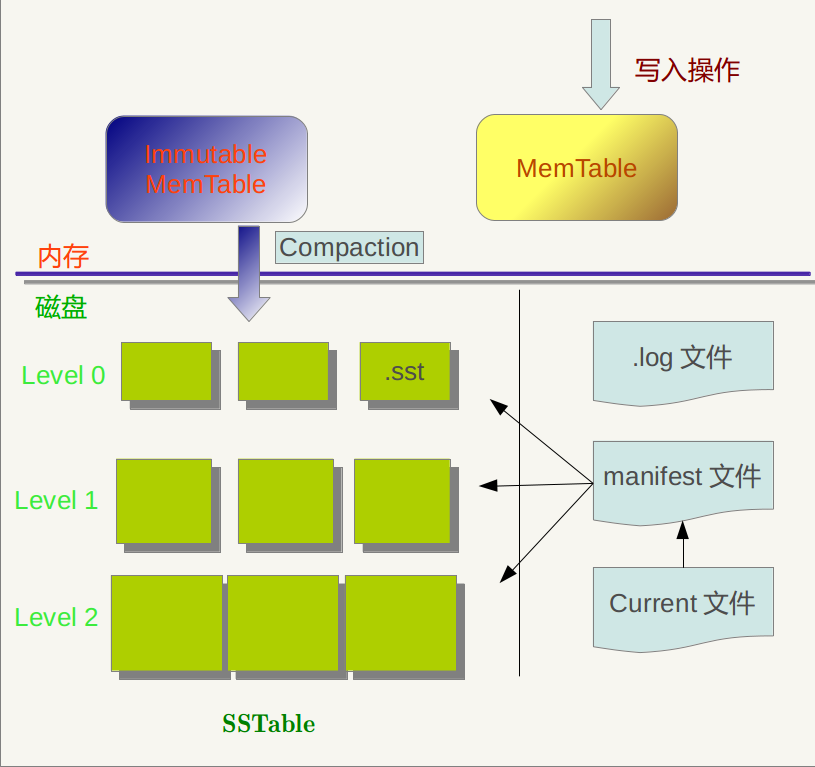
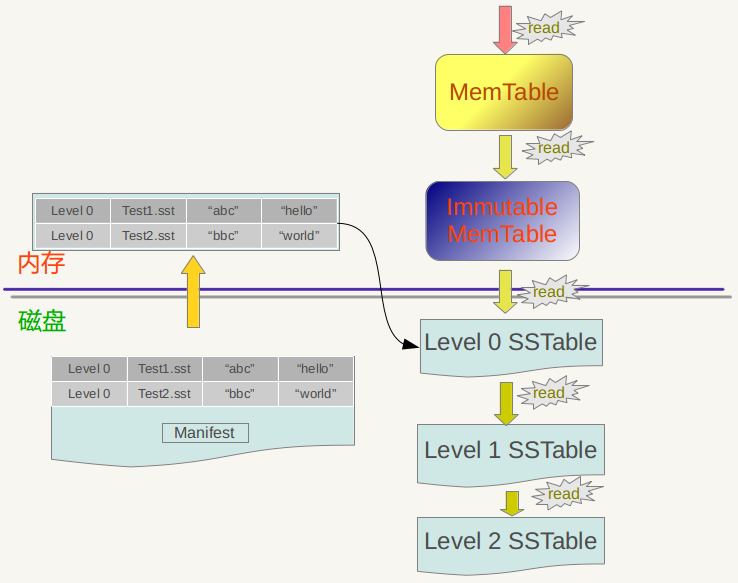
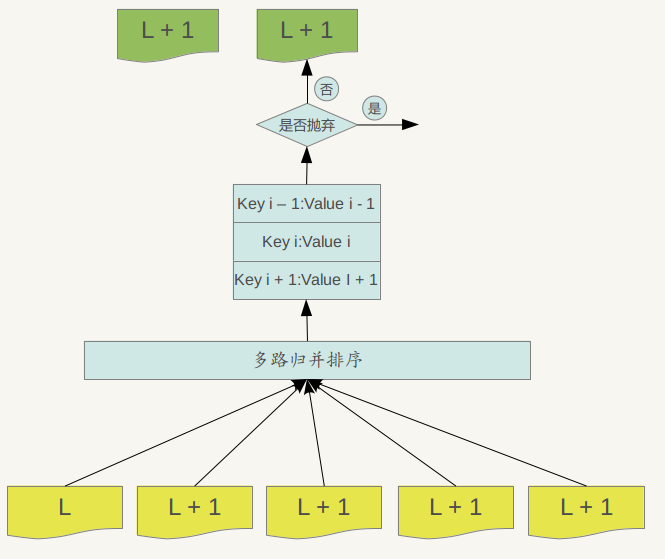
Major compaction的过程如下:对多个文件采用多路归并排序的方式,依次找出其中最小的Key记录,也就是对多个文件中的所有记录重新进行排序。之后采取一定的标准判断这个Key是否还需要保存,如果判断没有保存价值,那么直接抛掉,如果觉得还需要继续保存,那么就将其写入level L+1层中新生成的一个SSTable文件中。就这样对KV数据一一处理,形成了一系列新的L+1层数据文件,之前的L层文件和L+1层参与compaction 的文件数据此时已经没有意义了,所以全部删除。这样就完成了L层和L+1层文件记录的合并过程。
voiderrorcb(struct bufferevent *bev, short error, void *ctx) { if (error & BEV_EVENT_EOF) { /* connection has been closed, do any clean up here */ printf("connection closed\n"); }elseif (error & BEV_EVENT_ERROR){ /* check errno to see what error occurred */ printf("some other error\n"); } elseif (error & BEV_EVENT_TIMEOUT) /* must be a timeout event handle, handle it */ printf("Timed out\n"); } bufferevent_free(bev); }
ET 和 LT 的区别在于 LT 事件不会丢弃,而是只要读 buffer 里面有数据可以让用户读,则不断的通知你。而 ET 则只在事件发生之时通知。可以简单理解为 LT 是水平触发,而 ET 则为边缘触发。
ET 模式仅当状态发生变化的时候才获得通知,这里所谓的状态的变化并不包括缓冲区中还有未处理的数据,也就是说,如果要采用 ET 模式,需要一直 read/write 直到出错为止, 很多人反映为什么采用 ET 模式只接收了一部分数据就再也得不到通知了, 大多因为这样; 而 LT 模式是只要有数据没有处理就会一直通知下去的.
private: int m_iUserCount;//用户数量; structUserStatus *m_pAllUserStatus;//用户状态数组 int m_iEpollFd;//需要创建epollfd int m_iSockFd_UserId[_MAX_SOCKFD_COUNT];//将用户ID和socketid关联起来 int m_iPort;//端口号 char m_ip[100];//IP地址 };
if(a <= 4) { if(a <= 2) { if(a == 1) { /* a is 1 */ } else { /* a must be 2 */ } } else { if(a == 3) { /* a is 3 */ } else { /* a must be 4 */ } } } else { if(a <= 6) { if(a == 5) { /* a is 5 */ } else { /* a must be 6 */ } } else { if(a == 7) { /* a is 7 */ } else { /* a must be 8 */ } } }
慢速、低效:
c = getch();switch(c){ case 'A': { do something; break; } case 'H': { do something; break; } case 'Z': { do something; break; }}
快速、高效:
c = getch();switch(c) { case 0: { do something; break; } case 1: { do something; break; } case 2: { do something; break; }}
int main(void) { int i = 0; int limit = 33; /* could be anything */ int blocklimit;
/* The limit may not be divisible by BLOCKSIZE, go as near as we can first, then tidy up. */ blocklimit = (limit / BLOCKSIZE) * BLOCKSIZE;/* unroll the loop in blocks of 8 */ while(i < blocklimit) { printf("process(%d)\n", i); printf("process(%d)\n", i+1); printf("process(%d)\n", i+2); printf("process(%d)\n", i+3); printf("process(%d)\n", i+4); printf("process(%d)\n", i+5); printf("process(%d)\n", i+6); printf("process(%d)\n", i+7); /* update the counter */ i += 8; } /* * There may be some left to do. * This could be done as a simple for() loop, * but a switch is faster (and more interesting) */ if( i < limit ) { /* Jump into the case at the place that will allow * us to finish off the appropriate number of items. */ switch( limit - i ) { case 7 : printf("process(%d)\n", i); i++; case 6 : printf("process(%d)\n", i); i++; case 5 : printf("process(%d)\n", i); i++; case 4 : printf("process(%d)\n", i); i++; case 3 : printf("process(%d)\n", i); i++; case 2 : printf("process(%d)\n", i); i++; case 1 : printf("process(%d)\n", i); }} return 0;
}
计算非零位的个数 / counting the number of bits set
例1:测试单个的最低位,计数,然后移位。
//example1int countbit1(uint n){ int bits = 0; while (n != 0) { if(n & 1) bits++; n >>= 1; } return bits;}
例2:先除4,然后计算被4处的每个部分。循环拆解经常会给程序优化带来新的机会。
//example - 2int countbit2(uint n){ int bits = 0; while (n != 0) { if (n & 1) bits++; if (n & 2) bits++; if (n & 4) bits++; if (n & 8) bits++; n >>= 4; } return bits;}
int f1(int a, int b, int c, int d) { return a + b + c + d;}int g1(void) { return f1(1, 2, 3, 4);}int f2(int a, int b, int c, int d, int e, int f) { return a + b + c + d + e + f;}ing g2(void) { return f2(1, 2, 3, 4, 5, 6);}
Richard’s C Optimization page OR: How to make your C, C++ or Java program run faster with little effort.
Code Optimization Using the GNU C Compiler By Rahul U Joshi.
Compile C Faster on Linux [Christopher W. Fraser (Microsoft Research), David R. Hanson (Princeton University)]
CODE OPTIMIZATION – COMPILER [1] [2][Thanks to Craig Burley for the excellent comments. Thanks to Timothy Prince for the note on architectures with Instruction Level Parallelism].
An Evolutionary Analysis of GNU C Optimizations [Using Natural Selection to Investigate Software Complexities by Scott Robert Ladd. Updated: 16 December 2003]
]]>
虽然对于优化 C 代码有很多有效的指导方针,但是对于彻底地了解编译器和你工作的机器依然无法取代,通常,加快程序的速度也会加大代码量。这些增加的代码也会影响一个程序的复杂度和可读性,这是不可接受的,比如你在一些小型的设备上编程,例如:移动设备、PDA……,这些有着严格的内存限制,于是,在优化的座右铭是:写代码在内存和速度都应该优化。
C 语言高级编程指南http://miaopei.github.io/2016/07/03/Program-C/c-advaced-programming/2016-07-03T02:14:50.000Z2019-06-14T06:43:47.309Z整形溢出和提升
大部分 C 程序员都以为基本的整形操作都是安全的其实不然,看下面这个例子,
你觉得输出结果是什么:
1 2 3 4 5 6 7 8 9 10 11 12
intmain(int argc, char** argv){ long i = -1;
if (i < sizeof(i)) { printf("OK\n"); } else { printf("error\n"); }
“If the operand that has unsigned integer type has rank greater or equal to the rank of the type of the other operand, then the operand with signed integer type is converted to the type of the operand with unsigned integer type.”
“If the size of the space requested is 0, the behavior is implementation- defined: the value returned shall be either a null pointer or a unique pointer.”
1 2 3 4 5 6 7 8
size_t computed_size;
if (elem_size && num > SIZE_MAX / elem_size) { errno = ENOMEM; err(1, "overflow"); }
“In case of failure realloc shall return NULL and leave provided memory object intact. Thus it is important not only to check for integer overflow of size argument, but also to correctly handle object size if realloc fails.”
C++ 标准库有个 auto_ptr 智能指针,能够自动释放指针所指对象的内存,C++ boost 库有个boost::shared_ptr 智能指针,内置引用计数,支持拷贝和赋值,看下面这个例子:
“Objects of shared_ptr types have the ability of taking ownership of a pointer and share that ownership: once they take ownership, the group of owners of a pointer become responsible for its deletion when the last one of them releases that ownership.”
intmain() { std::array<int,5> a = {10, 20, 30, 40, 50}; std::array<int,5> b = {10, 20, 30, 40, 50}; std::array<int,5> c = {50, 40, 30, 20, 10};
if (a==b) std::cout << "a and b are equal\n"; if (b!=c) std::cout << "b and c are not equal\n"; if (b<c) std::cout << "b is less than c\n"; if (c>b) std::cout << "c is greater than b\n"; if (a<=b) std::cout << "a is less than or equal to b\n"; if (a>=b) std::cout << "a is greater than or equal to b\n";
return0; }
Output
1 2 3 4 5 6
a and b are equal b and c are not equal b is less than c c is greater than b a is less than or equal to b a is greater than or equal to b
intmain() { // constructors used in the same order as described above: std::vector<int> first; // empty vector of ints std::vector<int> second(4, 100); // four ints with value 100 std::vector<int> third(second.begin(), second.end());// iterating through second std::vector<int> fourth(third); // a copy of third
// the iterator constructor can also be used to construct from arrays: int myints[] = {16,2,77,29}; std::vector<int> fifth(myints, myints + sizeof(myints) / sizeof(int));
std::cout << "The contents of fifth are:"; for(std::vector<int>::iterator it = fifth.begin(); it != fifth.end(); ++it) std::cout << ' ' << *it; std::cout << '\n';
#include<vector> #include<string> #include<iostream> structPresident { std::string name; std::string country; int year; President(std::string p_name, std::string p_country, int p_year) : name(std::move(p_name)), country(std::move(p_country)), year(p_year) { std::cout << "I am being constructed.\n"; } President(President&& other) : name(std::move(other.name)), country(std::move(other.country)), year(other.year) { std::cout << "I am being moved.\n"; } President& operator=(const President& other) = default; }; intmain() { std::vector<President> elections; std::cout << "emplace_back:\n"; elections.emplace_back("Nelson Mandela", "South Africa", 1994); std::vector<President> reElections; std::cout << "\npush_back:\n"; reElections.push_back(President("Franklin Delano Roosevelt", "the USA", 1936)); std::cout << "\nContents:\n"; for (President const& president: elections) { std::cout << president.name << " was elected president of " << president.country << " in " << president.year << ".\n"; } for (President const& president: reElections) { std::cout << president.name << " was re-elected president of " << president.country << " in " << president.year << ".\n"; } }
Output
1 2 3 4 5 6 7 8 9 10
emplace_back: I am being constructed. push_back: I am being constructed. I am being moved. Contents: Nelson Mandela was elected president of South Africa in 1994. Franklin Delano Roosevelt was re-elected president of the USA in 1936.
// constructors used in the same order as described above: std::deque<int> first; // empty deque of ints std::deque<int> second (4,100); // four ints with value 100 std::deque<int> third (second.begin(),second.end()); // iterating through second std::deque<int> fourth (third); // a copy of third
// the iterator constructor can be used to copy arrays: int myints[] = {16,2,77,29}; std::deque<int> fifth (myints, myints + sizeof(myints) / sizeof(int) );
std::cout << "The contents of fifth are:"; for (std::deque<int>::iterator it = fifth.begin(); it!=fifth.end(); ++it) std::cout << ' ' << *it;
for (c='a'; c<'h'; c++) { std::cout << c; if (mymap.count(c)>0) std::cout << " is an element of mymap.\n"; else std::cout << " is not an element of mymap.\n"; }
return0; }
Output
1 2 3 4 5 6 7
a is an element of mymap. b is not an element of mymap. c is an element of mymap. d is not an element of mymap. e is not an element of mymap. f is an element of mymap. g is not an element of mymap.
一条 using 声明 语句一次只引入命名空间的一个成员。它使得我们可以清楚知道程序中所引用的到底是哪个名字。如:
1
using namespace_name::name;
构造函数的 using 声明【C++11】
在 C++11 中,派生类能够重用其直接基类定义的构造函数。
1 2 3 4 5
classDerived : Base { public: using Base::Base; /* ... */ };
如上 using 声明,对于基类的每个构造函数,编译器都生成一个与之对应(形参列表完全相同)的派生类构造函数。生成如下类型构造函数:
1
derived(parms) : base(args) { }
using 指示
using 指示 使得某个特定命名空间中所有名字都可见,这样我们就无需再为它们添加任何前缀限定符了。如:
1
using namespace_name name;
尽量少使用 using 指示 污染命名空间
一般说来,使用 using 命令比使用 using 编译命令更安全,这是由于它只导入了制定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译命令导入所有的名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。
using 使用
尽量少使用 using 指示
1
usingnamespacestd;
应该多使用 using 声明
1 2 3
int x; std::cin >> x ; std::cout << x << std::endl;
或者
1 2 3 4 5 6
usingstd::cin; usingstd::cout; usingstd::endl; int x; cin >> x; cout << x << endl;
intmain() { T* t = new T(); // 先内存分配 ,再构造函数 delete t; // 先析构函数,再内存释放 return0; }
定位 new
定位 new(placement new)允许我们向 new 传递额外的参数。
1 2 3 4
new (palce_address) type new (palce_address) type (initializers) new (palce_address) type [size] new (palce_address) type [size] { braced initializer list }
palce_address 是个指针
initializers 提供一个(可能为空的)以逗号分隔的初始值列表
delete this 合法吗?
Is it legal (and moral) for a member function to say delete this?
合法,但:
必须保证 this 对象是通过 new(不是 new[]、不是 placement new、不是栈上、不是全局、不是其他对象成员)分配的
Class unique_ptr 实现独占式拥有(exclusive ownership)或严格拥有(strict ownership)概念,保证同一时间内只有一个智能指针可以指向该对象。你可以移交拥有权。它对于避免内存泄漏(resource leak)——如 new 后忘记 delete ——特别有用。
shared_ptr
多个智能指针可以共享同一个对象,对象的最末一个拥有着有责任销毁对象,并清理与该对象相关的所有资源。
支持定制型删除器(custom deleter),可防范 Cross-DLL 问题(对象在动态链接库(DLL)中被 new 创建,却在另一个 DLL 内被 delete 销毁)、自动解除互斥锁
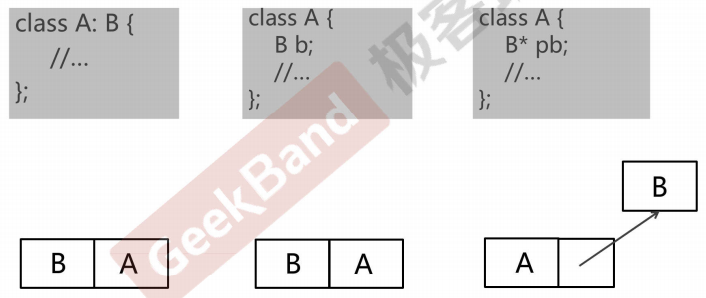
将文件间的编译依存关系降至最低(如果使用 object references 或 object pointers 可以完成任务,就不要使用 objects;如果能过够,尽量以 class 声明式替换 class 定义式;为声明式和定义式提供不同的头文件)
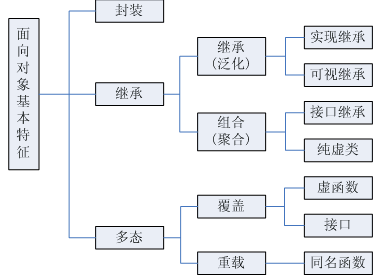
确定你的 public 继承塑模出 is-a 关系(适用于 base classes 身上的每一件事情一定适用于 derived classes 身上,因为每一个 derived class 对象也都是一个 base class 对象)
避免遮掩继承而来的名字(可使用 using 声明式或转交函数(forwarding functions)来让被遮掩的名字再见天日)
区分接口继承和实现继承(在 public 继承之下,derived classes 总是继承 base class 的接口;pure virtual 函数只具体指定接口继承;非纯 impure virtual 函数具体指定接口继承及缺省实现继承;non-virtual 函数具体指定接口继承以及强制性实现继承)
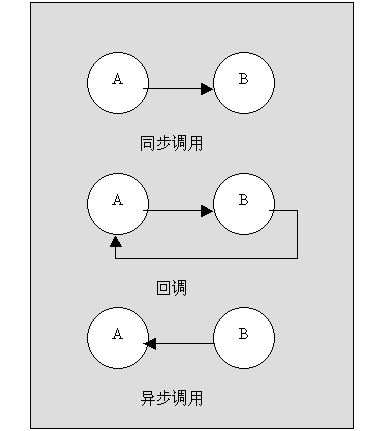
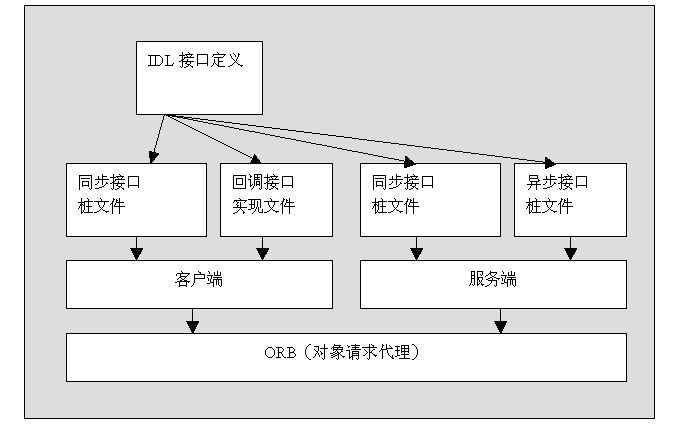
回调可用于通知机制,例如,有时要在程序中设置一个计时器,每到一定时间,程序会得到相应的通知,但通知机制的实现者对我们的程序一无所知。而此时,就需有一个特定原型的函数指针,用这个指针来进行回调,来通知我们的程序事件已经发生。实际上,SetTimer() API 使用了一个回调函数来通知计时器,而且,万一没有提供回调函数,它还会把一个消息发往程序的消息队列。
另一个使用回调机制的 API 函数是 EnumWindow() ,它枚举屏幕上所有的顶层窗口,为每个窗口调用一个程序提供的函数,并传递窗口的处理程序。如果被调用者返回一个值,就继续进行迭代,否则,退出。 EnumWindow() 并不关心被调用者在何处,也不关心被调用者用它传递的处理程序做了什么,它只关心返回值,因为基于返回值,它将继续执行或退出。
使用场景
不管怎么说,回调函数是继续自 C 语言的,因而,在 C++ 中,应只在与 C 代码建立接口,或与已有的回调接口打交道时,才使用回调函数。除了上述情况,在 C++ 中应使用虚拟方法或函数符( functor ),而不是回调函数。
voidbubble_sort(T arr[], int len){ int i, j; for (i = 0; i < len - 1; i++){ for (j = 0; j < len - 1 - i; j++) if (arr[j] > arr[j + 1]) swap(arr[j], arr[j + 1]); } }
intmain(){ int arr[] = { 61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62 }; int len = (int) sizeof(arr) / sizeof(*arr); bubble_sort(arr, len); for (int i = 0; i < len; i++) cout << arr[i] << ' '; cout << endl; float arrf[] = { 17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.8, 5.4 }; len = (int) sizeof(arrf) / sizeof(*arrf); bubble_sort(arrf, len); for (int i = 0; i < len; i++) cout << arrf[i] << ' '; return0; }
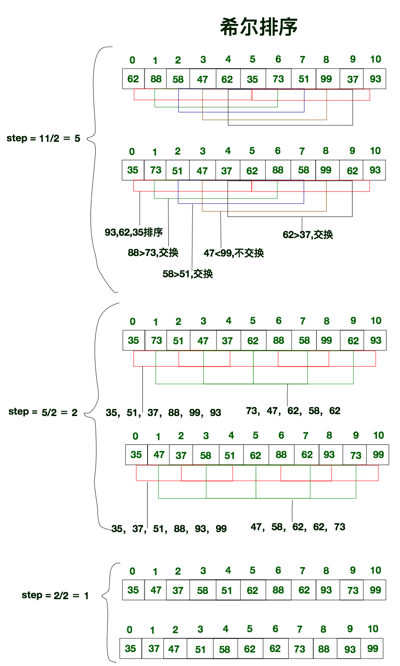
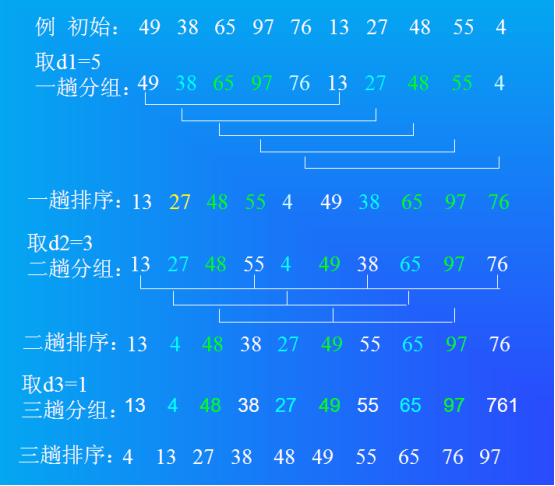
voidshell_sort(T array[], int length){ int h = 1; while (h < length / 3) { h = 3 * h + 1; } while (h >= 1) { for (int i = h; i < length; i++) { for (int j = i; j >= h && array[j] < array[j - h]; j -= h) { std::swap(array[j], array[j - h]); } } h = h / 3; } }
intmain(){ int arrf[] = { 13,14,94,33,82,25,59,94,65,23,45,27,73,25,39,10 }; int len = (int) sizeof(arrf) / sizeof(*arrf); shell_sort(arrf,len); for (int i = 0; i < len; i++) cout << arrf[i] << ' '; return0; }
五 归并排序
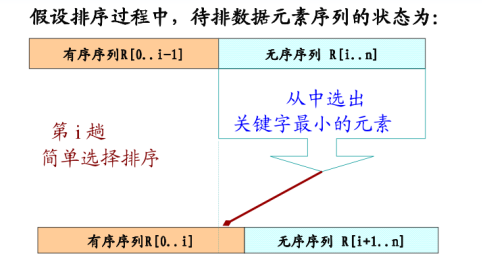
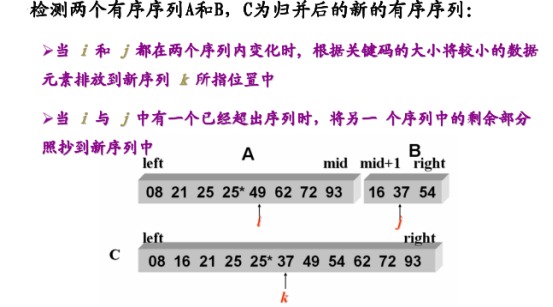
归并排序英文称为Merge Sort,归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。它首先将数据样本拆分为两个子数据样本, 并分别对它们排序, 最后再将两个子数据样本合并在一起; 拆分后的两个子数据样本序列, 再继续递归的拆分为更小的子数据样本序列, 再分别进行排序, 直到最后数据序列为1,而不再拆分,此时即完成对数据样本的最终排序。
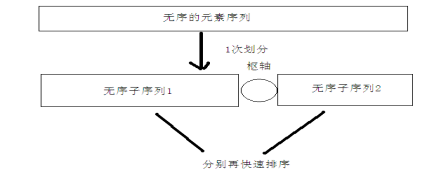
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。首先从数列中挑出一个元素,并将这个元素称为「基准」,英文pivot。重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。之后,在子序列中继续重复这个方法,直到最后整个数据序列排序完成。
structRange { int start, end; Range(int s = 0, int e = 0) { start = s, end = e; } };
template <typename T> // voidquick_sort(T arr[], constint len){ if (len <= 0) return; // Range r[len]; int p = 0; r[p++] = Range(0, len - 1); while (p) { Range range = r[--p]; if (range.start >= range.end) continue; T mid = arr[range.end]; int left = range.start, right = range.end - 1; while (left < right) { while (arr[left] < mid && left < right) left++; while (arr[right] >= mid && left < right) right--; std::swap(arr[left], arr[right]); } if (arr[left] >= arr[range.end]) std::swap(arr[left], arr[range.end]); else left++; r[p++] = Range(range.start, left - 1); r[p++] = Range(left + 1, range.end); } }
template <typename T> voidquick_sort_recursive(T arr[], int start, int end){ if (start >= end) return; T mid = arr[end]; int left = start, right = end - 1; while (left < right) { while (arr[left] < mid && left < right) left++; while (arr[right] >= mid && left < right) right--; std::swap(arr[left], arr[right]); } if (arr[left] >= arr[end]) std::swap(arr[left], arr[end]); else left++; quick_sort_recursive(arr, start, left - 1); quick_sort_recursive(arr, left + 1, end); }
template <typename T> // voidquick_sort(T arr[], int len){ quick_sort_recursive(arr, 0, len - 1); }
voidmax_heapify(int arr[], int start, int end){ //建立父节点指标和子节点指标 int dad = start; int son = dad * 2 + 1; while (son <= end) { //子节点指标在范围内才做比较 if (son + 1 <= end && arr[son] < arr[son + 1]) //比较两个子节点大小,选择最大的 son++; if (arr[dad] > arr[son]) //如果父节点大于子节点代表调整完毕,直接跳出函数 return; else { //否則交换父子内容再继续子节点和孙节点比较 swap(arr[dad], arr[son]); dad = son; son = dad * 2 + 1; } } }
voidheap_sort(int arr[], int len){ //初始化,i从最后一个父节点开始调整 for (int i = len / 2 - 1; i >= 0; i--) max_heapify(arr, i, len - 1); //先將第一个元素和已经排好的元素前一位做交换,再重调整,(刚调整的元素之前的元素),直到排序完毕 for (int i = len - 1; i > 0; i--) { swap(arr[0], arr[i]); max_heapify(arr, 0, i - 1); } }
intmaxbit(int data[], int n)//辅助函数,求数据的最大位数 { int maxData = data[0];///< 最大数 /// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。 for (int i = 1; i < n; ++i) { if (maxData < data[i]) maxData = data[i]; } int d = 1; int p = 10; while (maxData >= p) { //p *= 10; // Maybe overflow maxData /= 10; ++d; } return d; /* int d = 1; //保存最大的位数 int p = 10; for(int i = 0; i < n; ++i) { while(data[i] >= p) { p *= 10; ++d; } } return d;*/ }
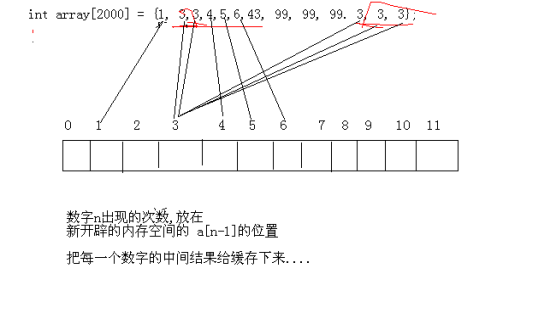
方法2: voidsearch(int a[], int len){ int sp[1000] = {0}; int i = 0; int max = 0; for(i=0; i<len; i++){ int index = a[i] - 1; sp[index]++; } for(i=0; i<1000; i++){ if( max < sp[i] ) max = sp[i]; } for(i=0; i<1000; i++){ if( max == sp[i] ) printf("%d\n", i+1); } }
C99标准: char p = “abc”; defines p with type ‘‘pointer to char’’ and initializes it to point to an object with type ‘‘array of char’’ with length 4 whose elements are initialized with a character string literal. *If an attempt is made to use p to modify the contents of the array, the behavior is undefined**.
#include<stdio.h> int *func(){ int n = 100; return &n; } intmain(){ int *p = func(), n; n = *p; printf("value = %d\n", n); return0; }
运行结果:
1
value = 100
n 是 func() 内部的局部变量,func() 返回了指向 n 的指针,根据上面的观点,func() 运行结束后 n 将被销毁,使用 *p 应该获取不到 n 的值。但是从运行结果来看,我们的推理好像是错误的,func() 运行结束后 *p 依然可以获取局部变量 n 的值,这个上面的观点不是相悖吗?
#include<stdio.h> int *func(){ int n = 100; return &n; } intmain(){ int *p = func(), n; printf("c.biancheng.net\n"); n = *p; printf("value = %d\n", n); return0; }
运行结果:
1 2
c.biancheng.net value = -2
可以看到,现在 p 指向的数据已经不是原来 n 的值了,它变成了一个毫无意义的甚至有些怪异的值。与前面的代码相比,该段代码仅仅是在 *p 之前增加了一个函数调用,这一细节的不同却导致运行结果有天壤之别,究竟是为什么呢?
前面我们说函数运行结束后会销毁所有的局部数据,这个观点并没错,大部分C语言教材也都强调了这一点。但是,这里所谓的销毁并不是将局部数据所占用的内存全部抹掉,而是程序放弃对它的使用权限,弃之不理,后面的代码可以随意使用这块内存。对于上面的两个例子,func() 运行结束后 n 的内存依然保持原样,值还是 100,如果使用及时也能够得到正确的数据,如果有其它函数被调用就会覆盖这块内存,得到的数据就失去了意义。
int arr[10]; //arr = NULL; //arr作为指针常量,不可修改 int *p = arr; //此时arr作为指针常量来使用 printf("sizeof(arr):%d\n", sizeof(arr)); //此时sizeof结果为整个数组的长度 printf("&arr type is %s\n", typeid(&arr).name()); //int(*)[10]而不是int*
ArrayType myarr; //等价于 int myarr[10]; ArrayType* pArr = &arr; //定义了一个数组指针pArr,并且指针指向数组arr for (int i = 0; i < 10;i++){ printf("%d ",(*pArr)[i]); } printf("\n"); }
//方式二 voidtest02(){
int arr[10]; //定义数组指针类型 typedef int(*ArrayType)[10]; ArrayType pArr = &arr; //定义了一个数组指针pArr,并且指针指向数组arr for (int i = 0; i < 10; i++){ (*pArr)[i] = i + 1; } for (int i = 0; i < 10; i++){ printf("%d ", (*pArr)[i]); } printf("\n");
}
//方式三 voidtest03(){
int arr[10]; int(*pArr)[10] = &arr;
for (int i = 0; i < 10; i++){ (*pArr)[i] = i + 1;
} for (int i = 0; i < 10; i++){ printf("%d ", (*pArr)[i]); } printf("\n"); }
$ gcc -shared -fPIC -o libmyhello.so hello.o /usr/bin/ld: hello.o: relocation R_X86_64_32 against `.rodata' can not be used when making a shared object; recompile with -fPIC hello.o: could not read symbols: Bad value collect2: ld returned 1 exit status
正确方法是,这样就可以了:
1 2 3 4 5
$ gcc -fPIC -shared -o libmyhello.so hello.c
# 已生成libmyhello.so,是绿色。 $ ls hello.c hello.h libmyhello.so main.c
//void printArrary(int a[10], int n) //void printArrary(int a[], int n) voidprintArrary(int *a, int n) { int i = 0; for (i = 0; i < n; i++) { printf("%d, ", a[i]); } printf("\n"); }
intmain() { int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; int n = sizeof(a) / sizeof(a[0]);
//void set_stu_pro(struct stu tmp[100], int n) //void set_stu_pro(struct stu tmp[], int n) voidset_stu_pro(struct stu *tmp, int n) { int i = 0; for (i = 0; i < n; i++) { sprintf(tmp->name, "name%d%d%d", i, i, i); tmp->age = 20 + i; tmp++; } }
intmain() { structstus[3] = {0 }; int i = 0; int n = sizeof(s) / sizeof(s[0]); set_stu_pro(s, n); //数组名传递
for (i = 0; i < n; i++) { printf("%s, %d\n", s[i].name, s[i].age); }
在C语言中,EOF表示文件结束符(end of file)。在while循环中以EOF作为文件结束标志,这种以EOF作为文件结束标志的文件,必须是文本文件。在文本文件中,数据都是以字符的ASCII代码值的形式存放。我们知道,ASCII代码值的范围是0~127,不可能出现-1,因此可以用EOF作为文件结束标志。#define EOF (-1)
$ nm hello1.o 0000000000000000 T test $ nm hello2.o 0000000000000000 T _Z4testiPc
从上面信息可以看出,C 语言编译后的函数符号还是原函数名,而 C++ 编译后的函数符号由test变成了 _Z4testiPc,从这个符号名字可以看出 test 前面有个数字 4 应该是函数名长度,test 后面 iPc 应该就是函数的参数签名。C++ 之所以这样规定编译后的函数符号是因为对面对象的 C++ 具有函数重载功能,以此来区分不同的函数。
# 选项参数 a<成员文件> 将文件插入备存文件中指定的成员文件之后。 b<成员文件> 将文件插入备存文件中指定的成员文件之前。 c 建立备存文件。 f 为避免过长的文件名不兼容于其他系统的ar指令指令,因此可利用此参数,截掉要放入备存文件中过长的成员文件名称。 i<成员文件> 将问家插入备存文件中指定的成员文件之前。 o 保留备存文件中文件的日期。 s 若备存文件中包含了对象模式,可利用此参数建立备存文件的符号表。 S 不产生符号表。 u 只将日期较新文件插入备存文件中。 v 程序执行时显示详细的信息。 V 显示版本信息。
CPThread.o: 00000068 T Main__8CPThreadPv 00000038 T Start__8CPThread 00000014 T _._8CPThread 00000000 T __8CPThread 00000000 ? __FRAME_BEGIN__ ....................................... # 则nm -A 的输出如下: libtest.a:CPThread.o:00000068 T Main__8CPThreadPv libtest.a:CPThread.o:00000038 T Start__8CPThread libtest.a:CPThread.o:00000014 T _._8CPThread libtest.a:CPThread.o:00000000 T __8CPThread libtest.a:CPThread.o:00000000 ? __FRAME_BEGIN__ ..................................................................
# 修改 /etc/sudoers 文件,找到下面一行,在 root 下面添加一行,如下所示: ## Allow root to run any commands anywhere root ALL=(ALL) ALL tommy ALL=(ALL) ALL # 修改完毕,现在可以用 tommy 帐号登录,然后用命令 sudo – ,即可获得 root 权限进行操作。
# 参数: -a file 从文件中读入作为sdtin -e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。 -p 当每次执行一个argument的时候询问一次用户。 -n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。 -t 表示先打印命令,然后再执行。 -i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。 -r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。 -s num 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。 -L num 从标准输入一次读取 num 行送给 command 命令。 -l 同 -L。 -d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。 -x exit的意思,主要是配合-s使用。。 -P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧。



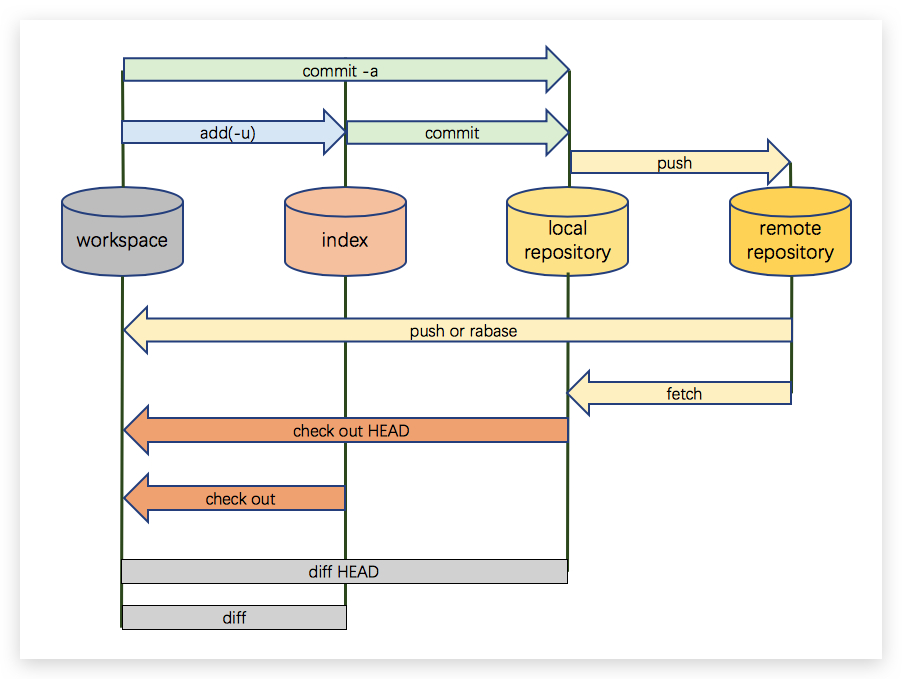
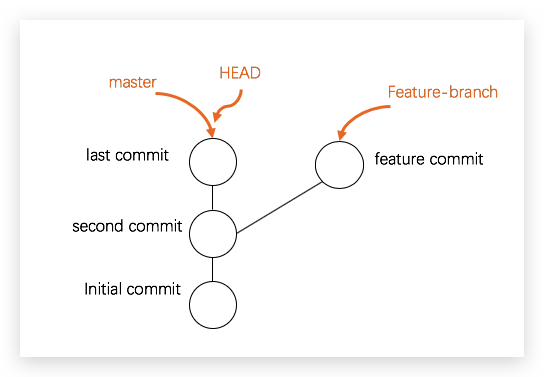
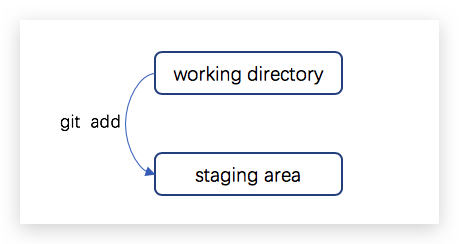
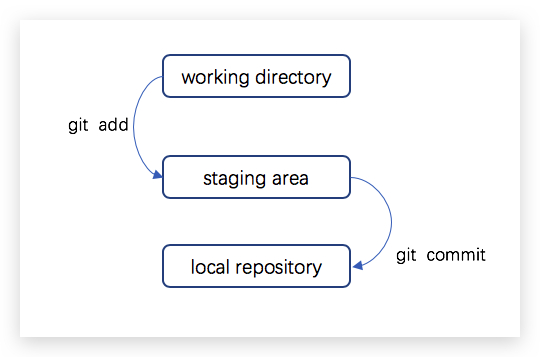
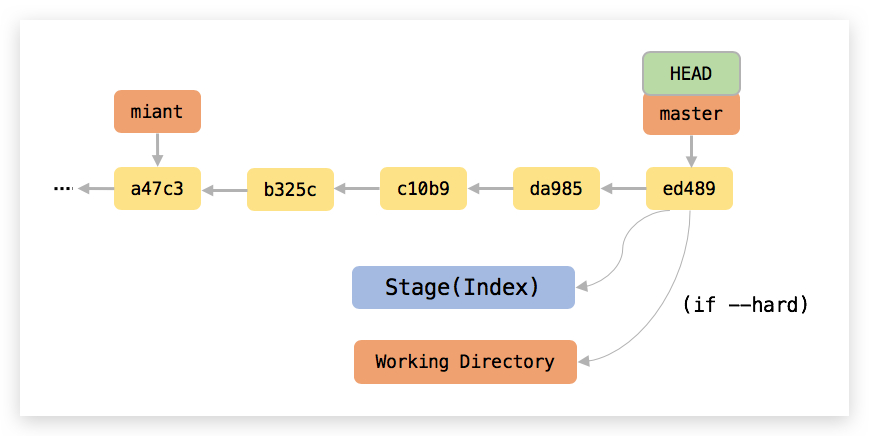
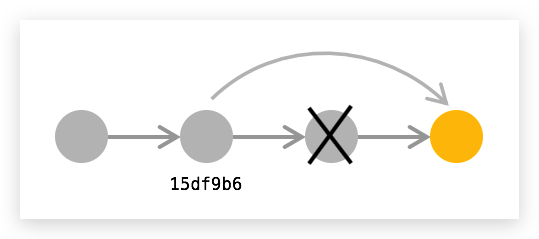
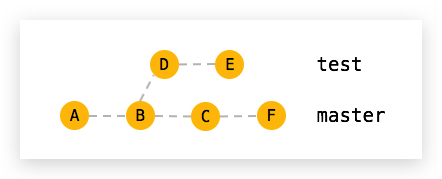
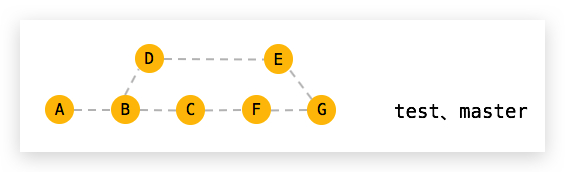
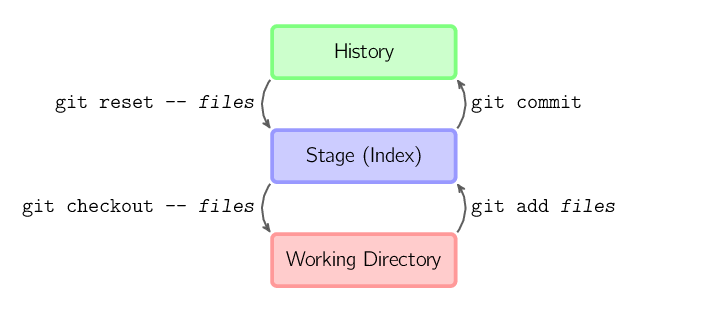
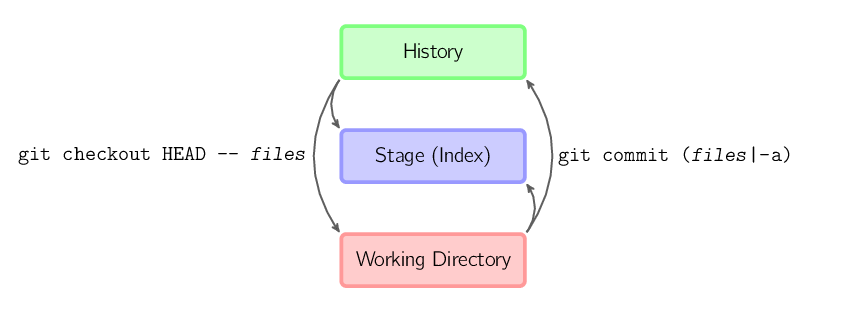
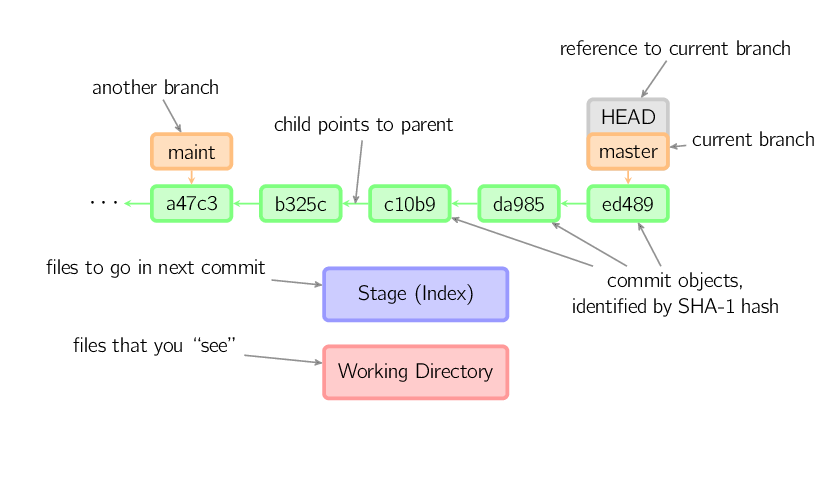
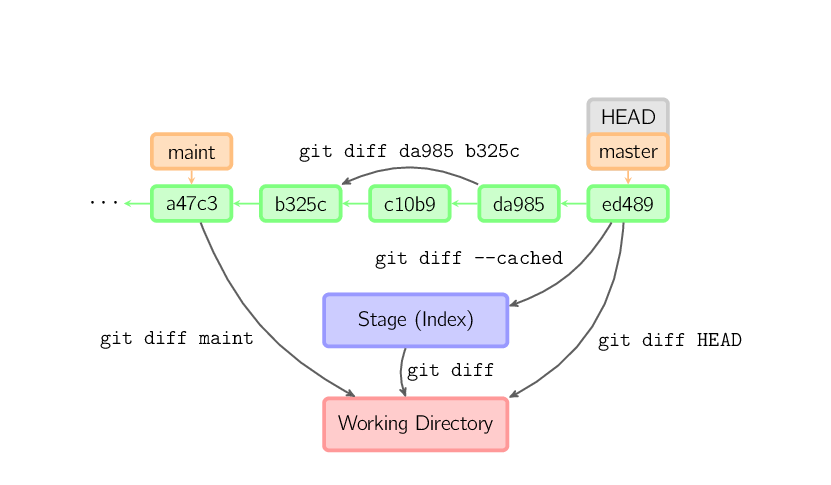
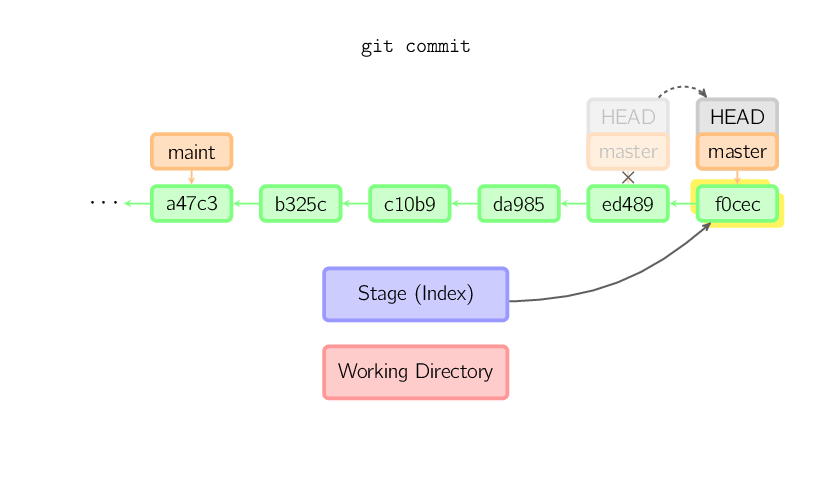
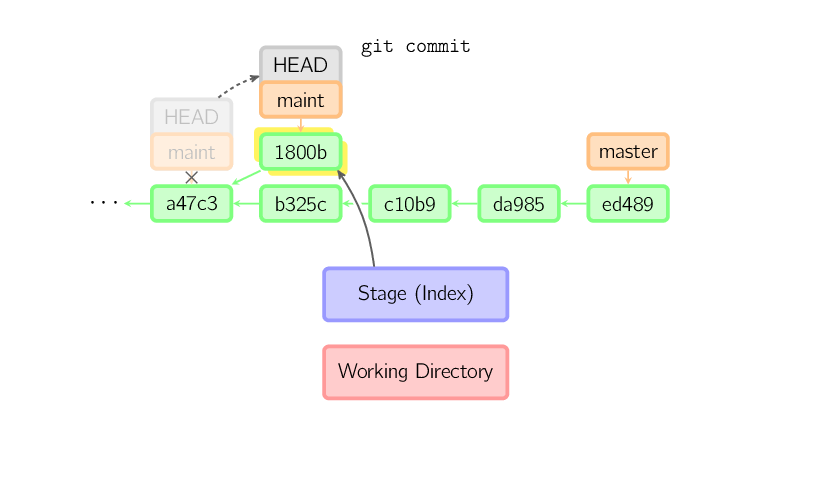
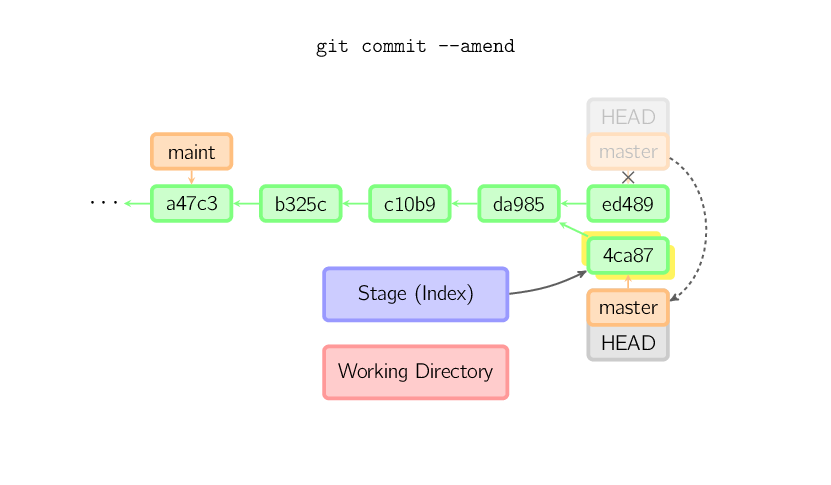
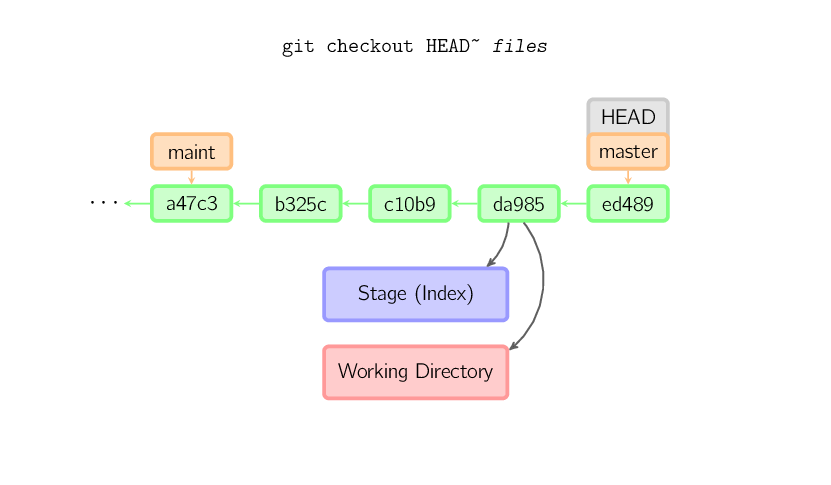
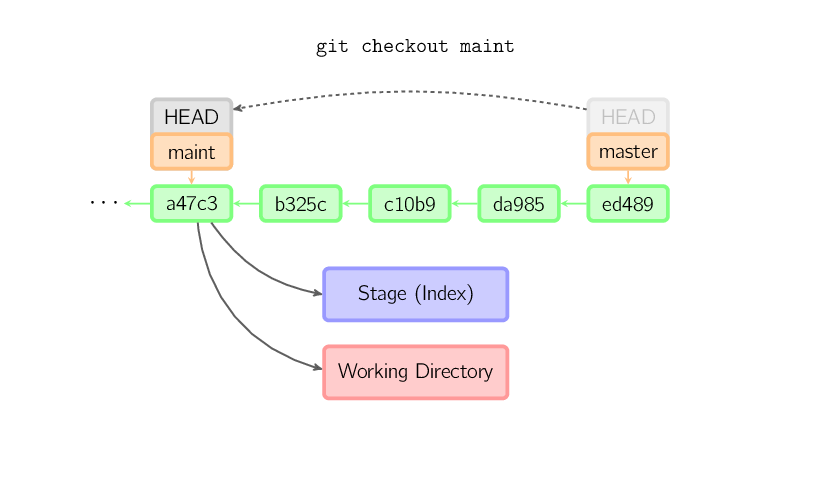
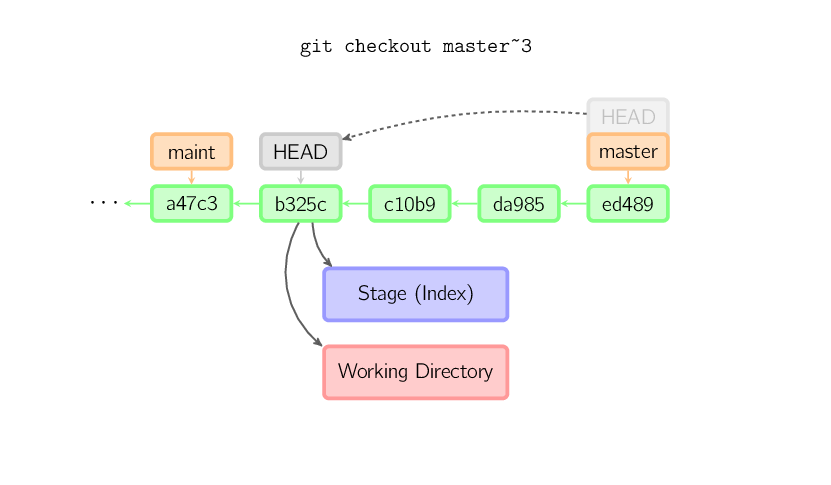
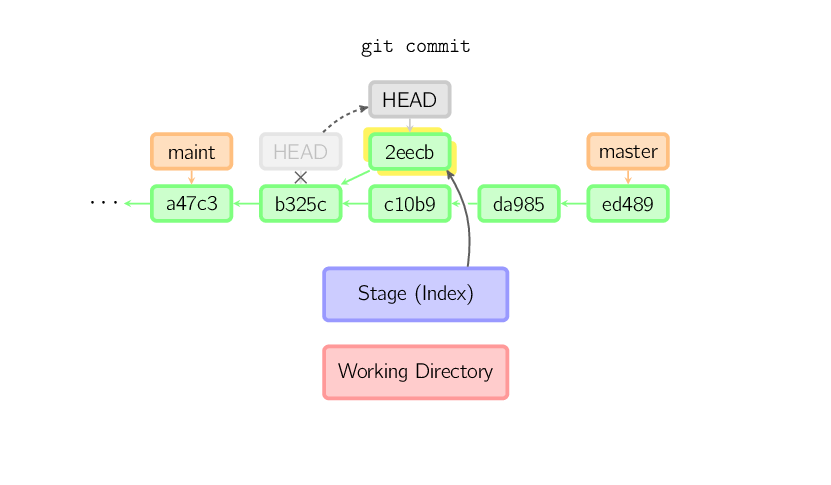
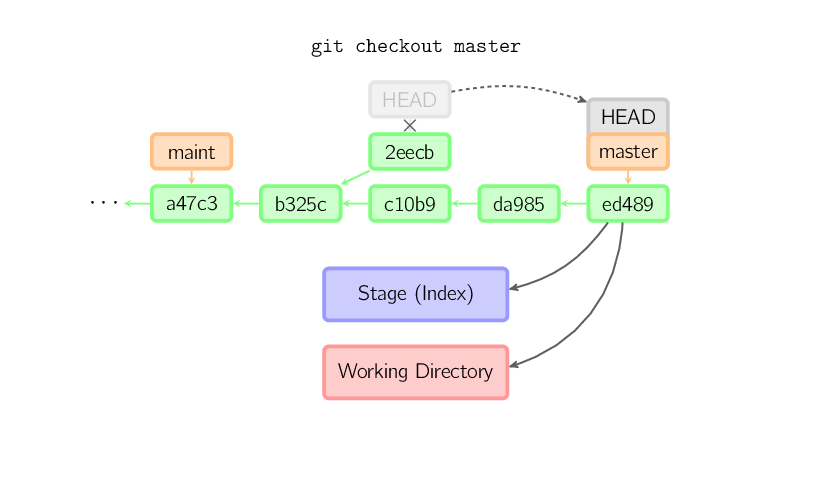
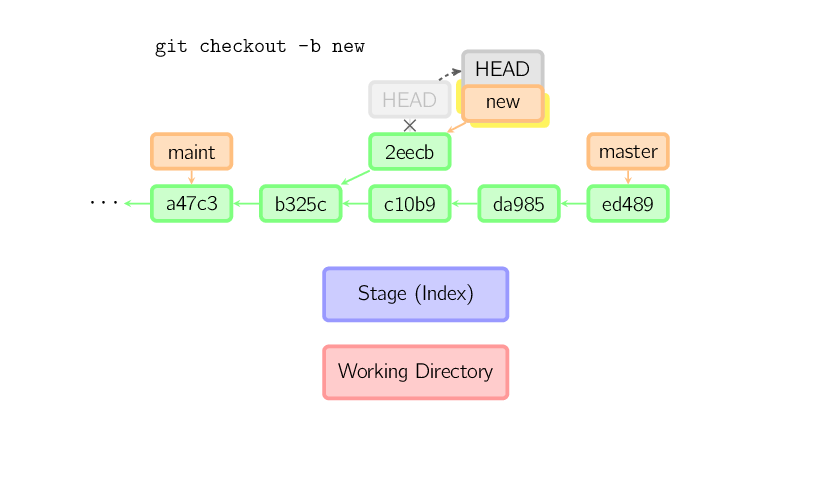
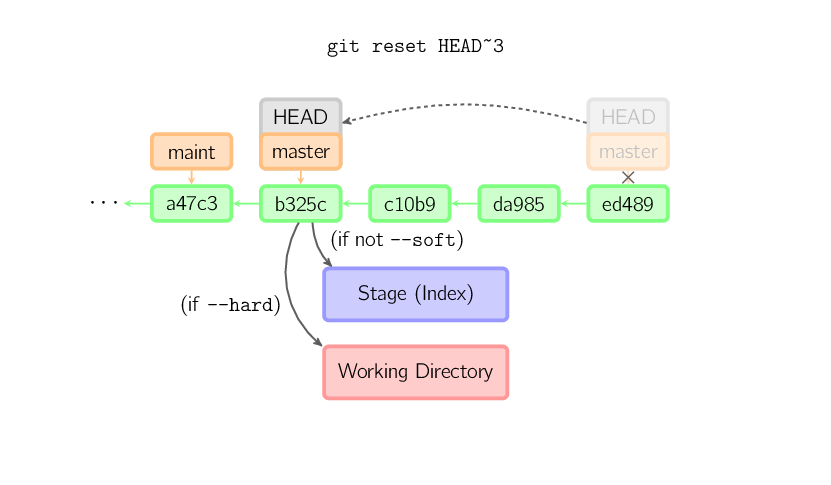
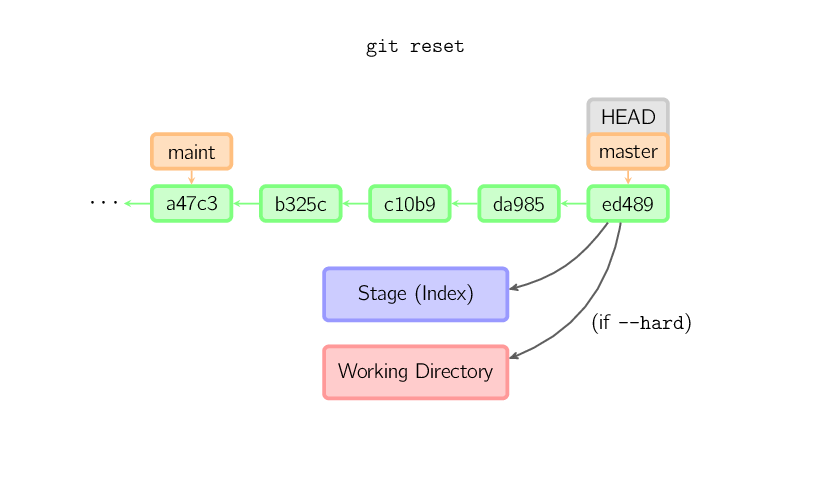
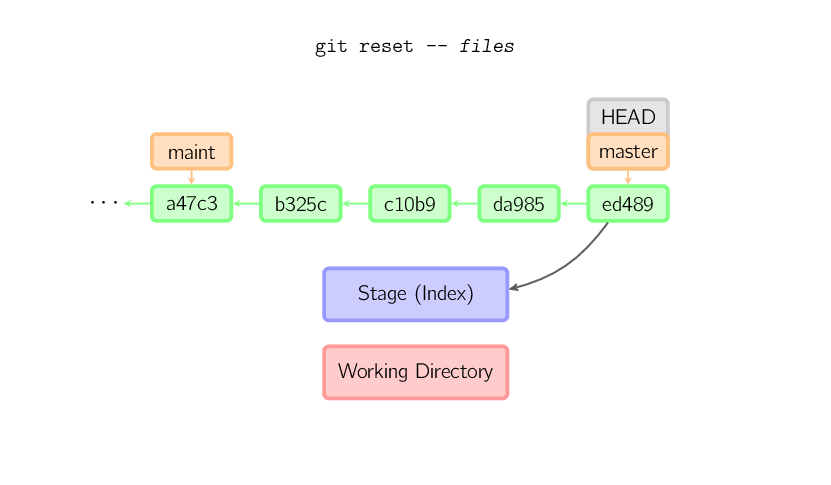
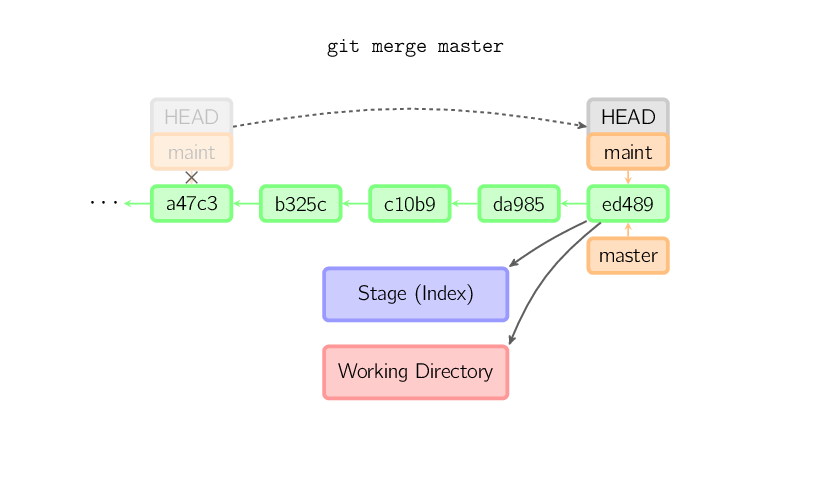
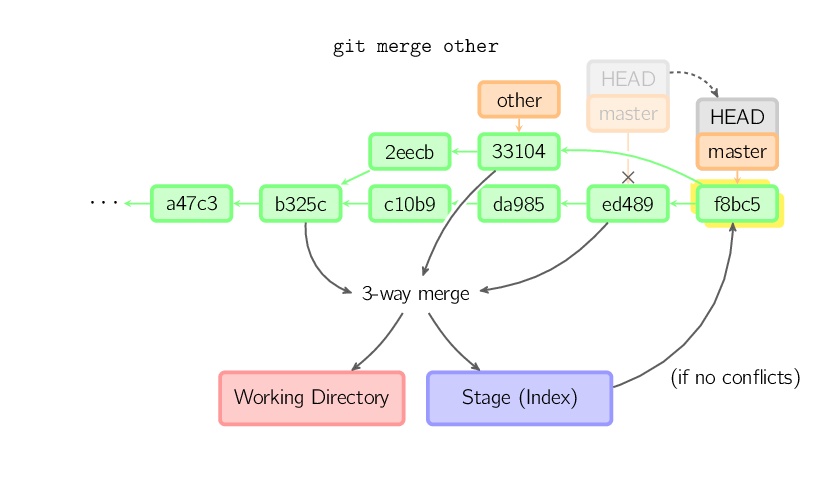
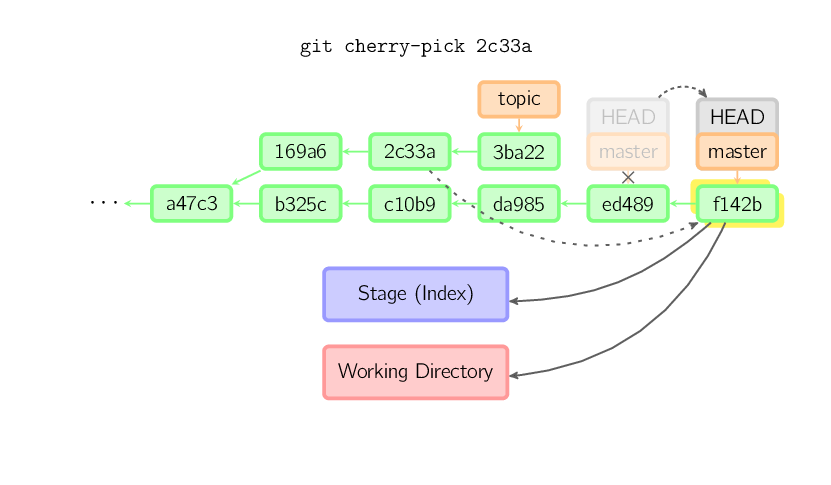
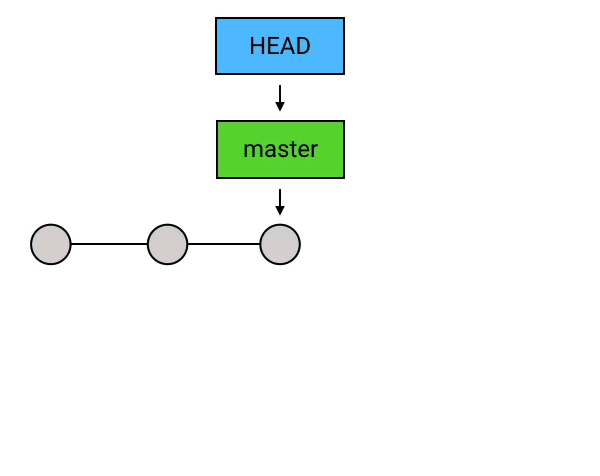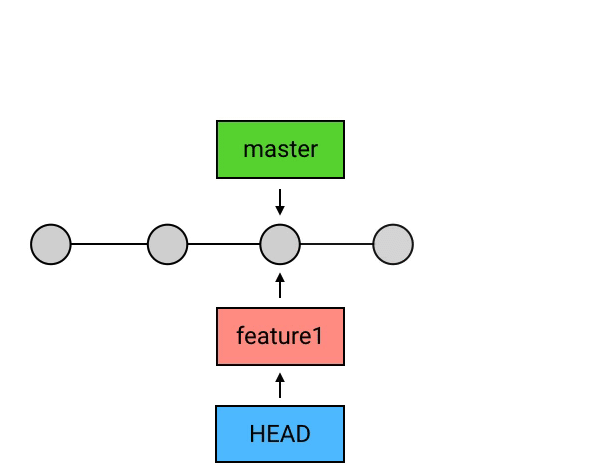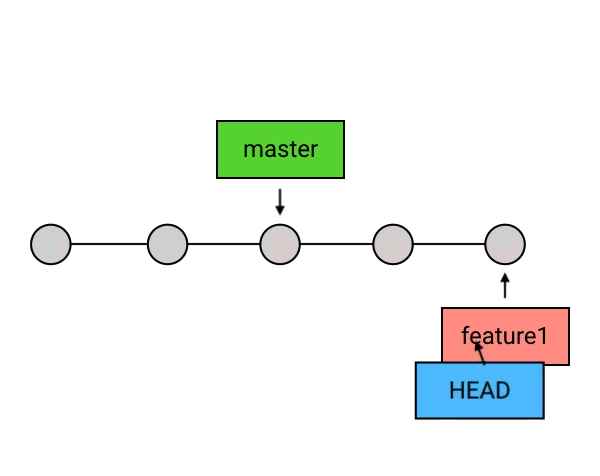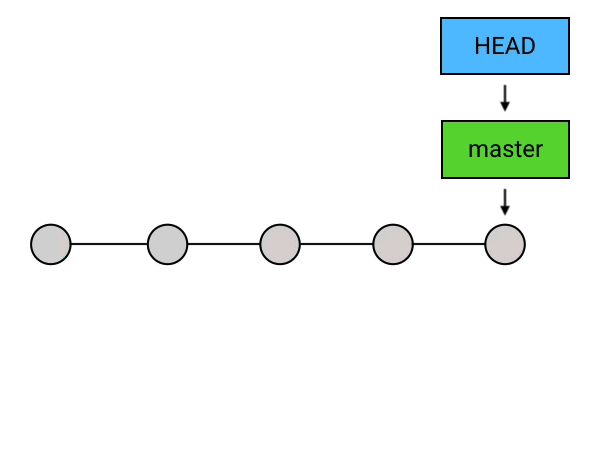
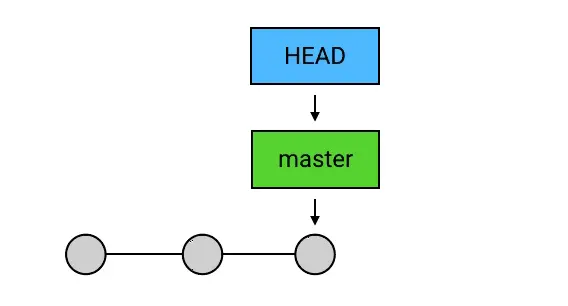
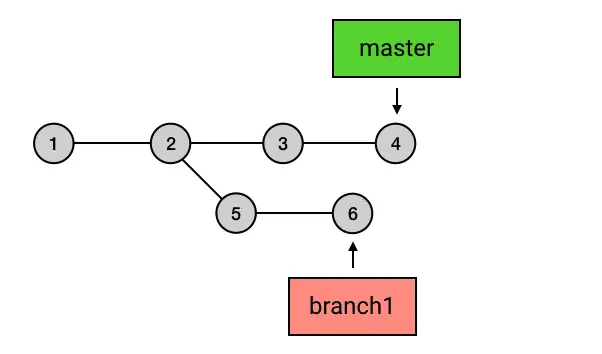
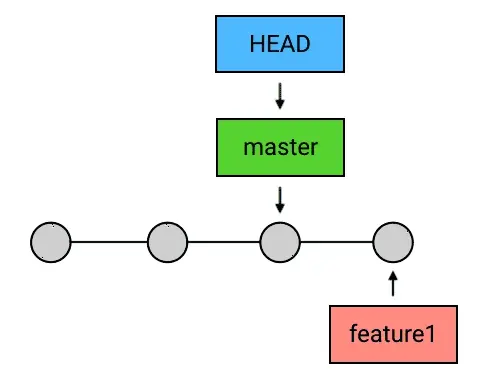
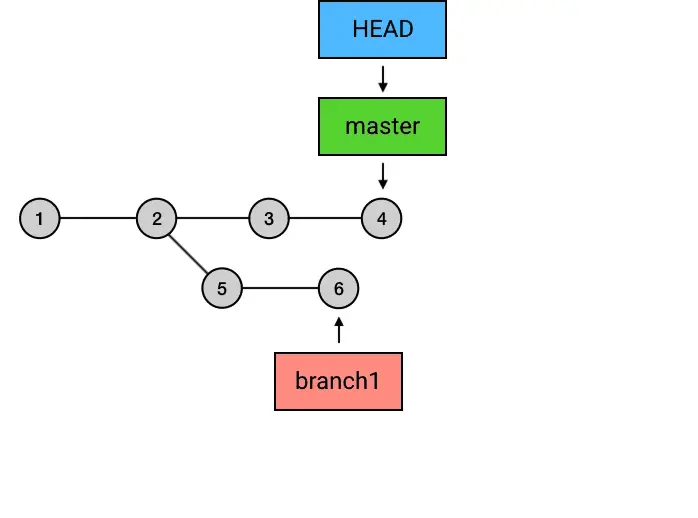
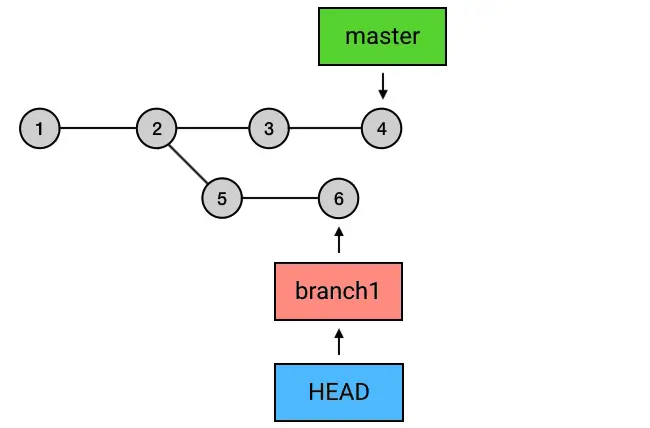
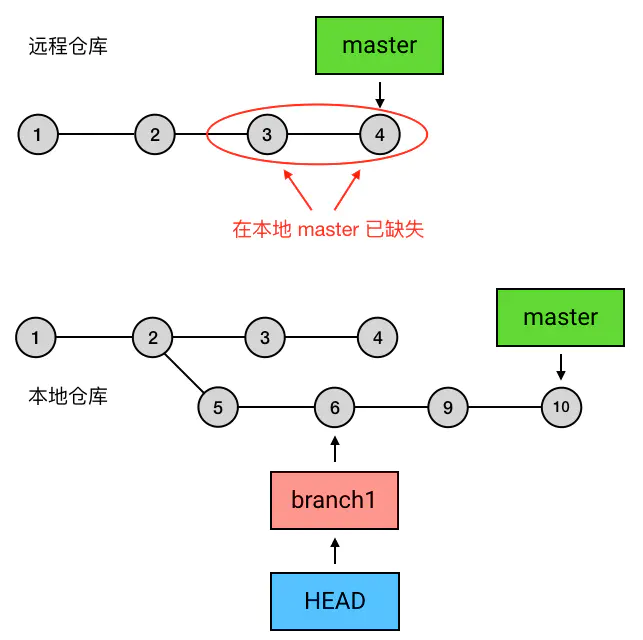






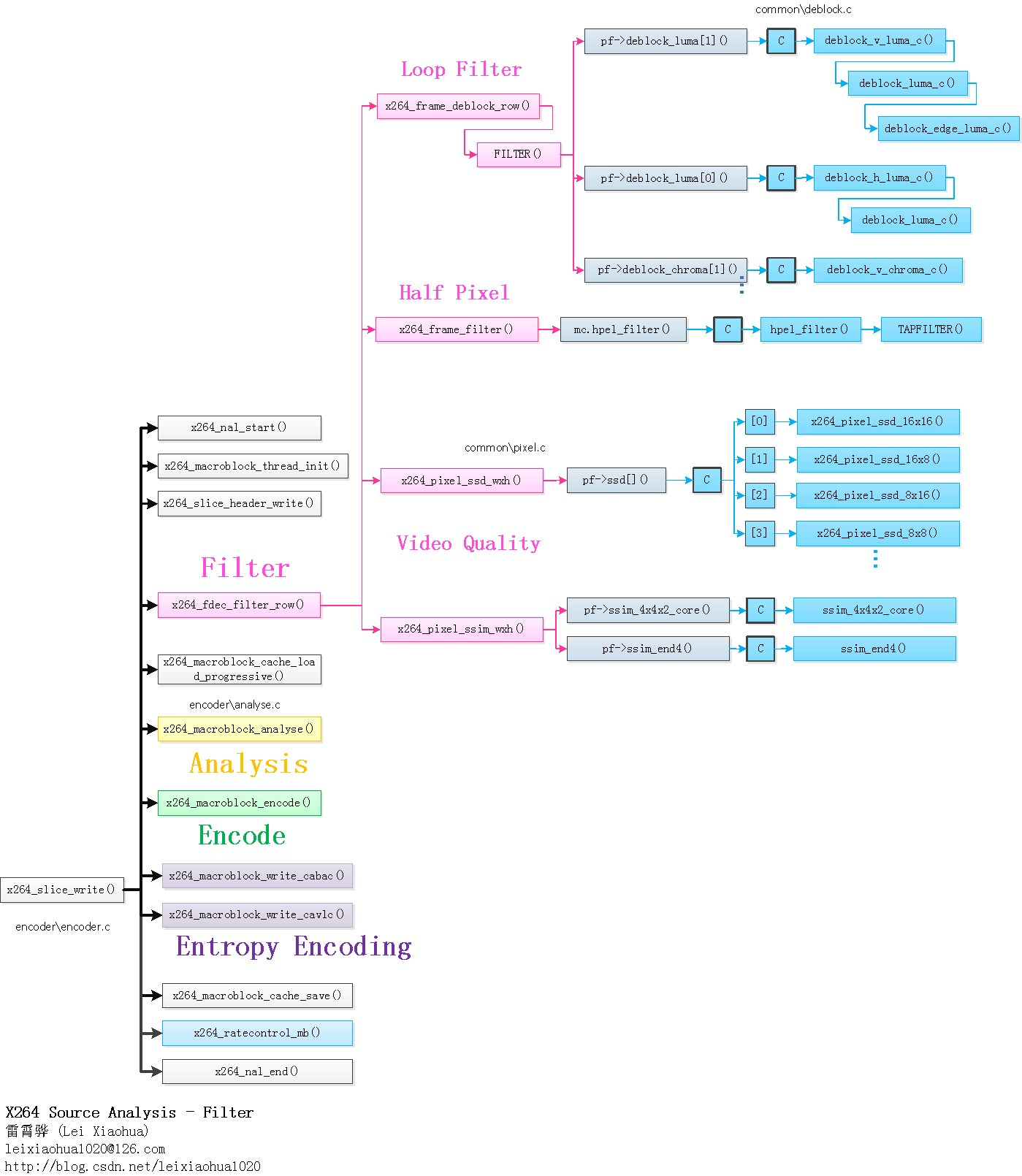
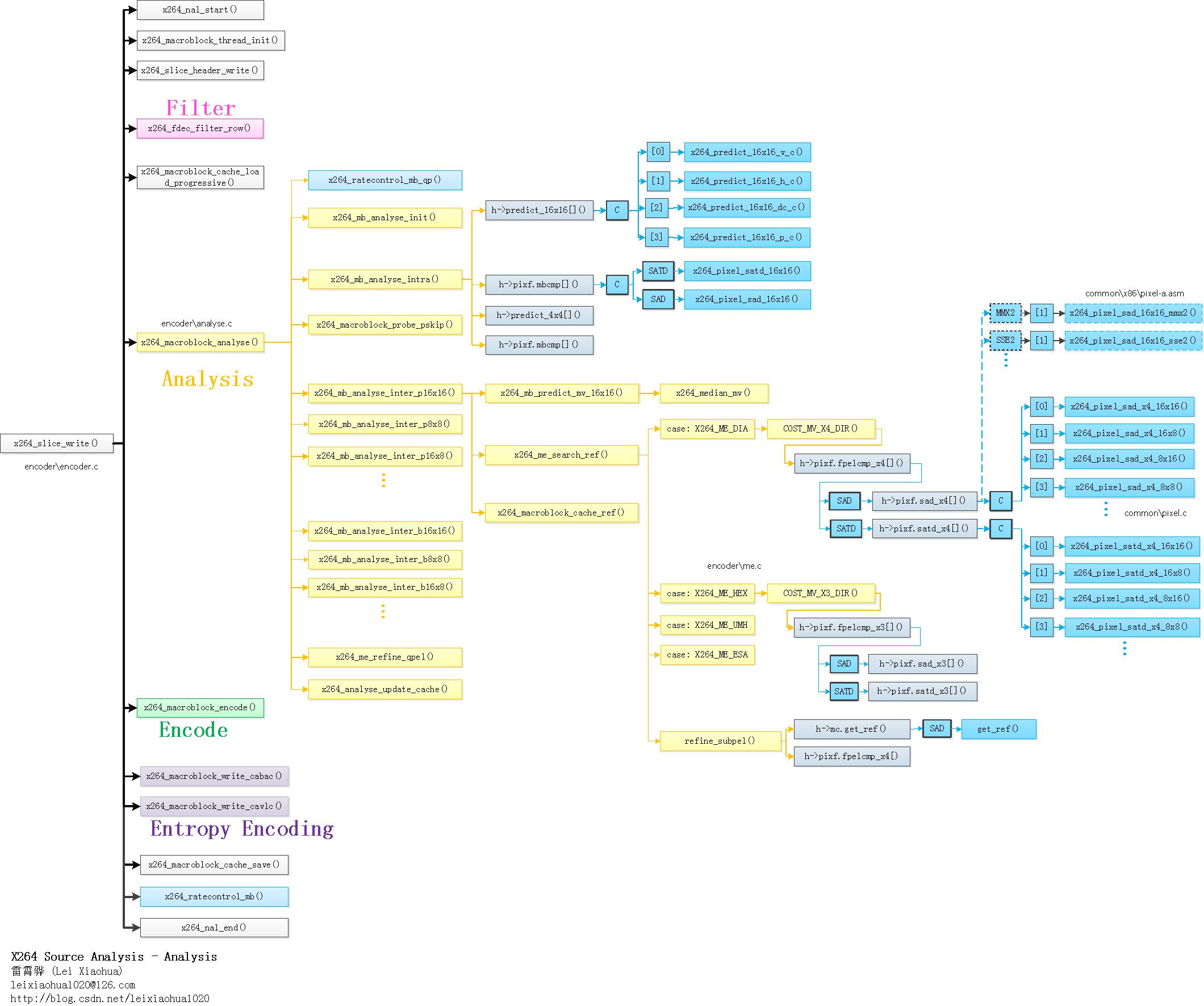
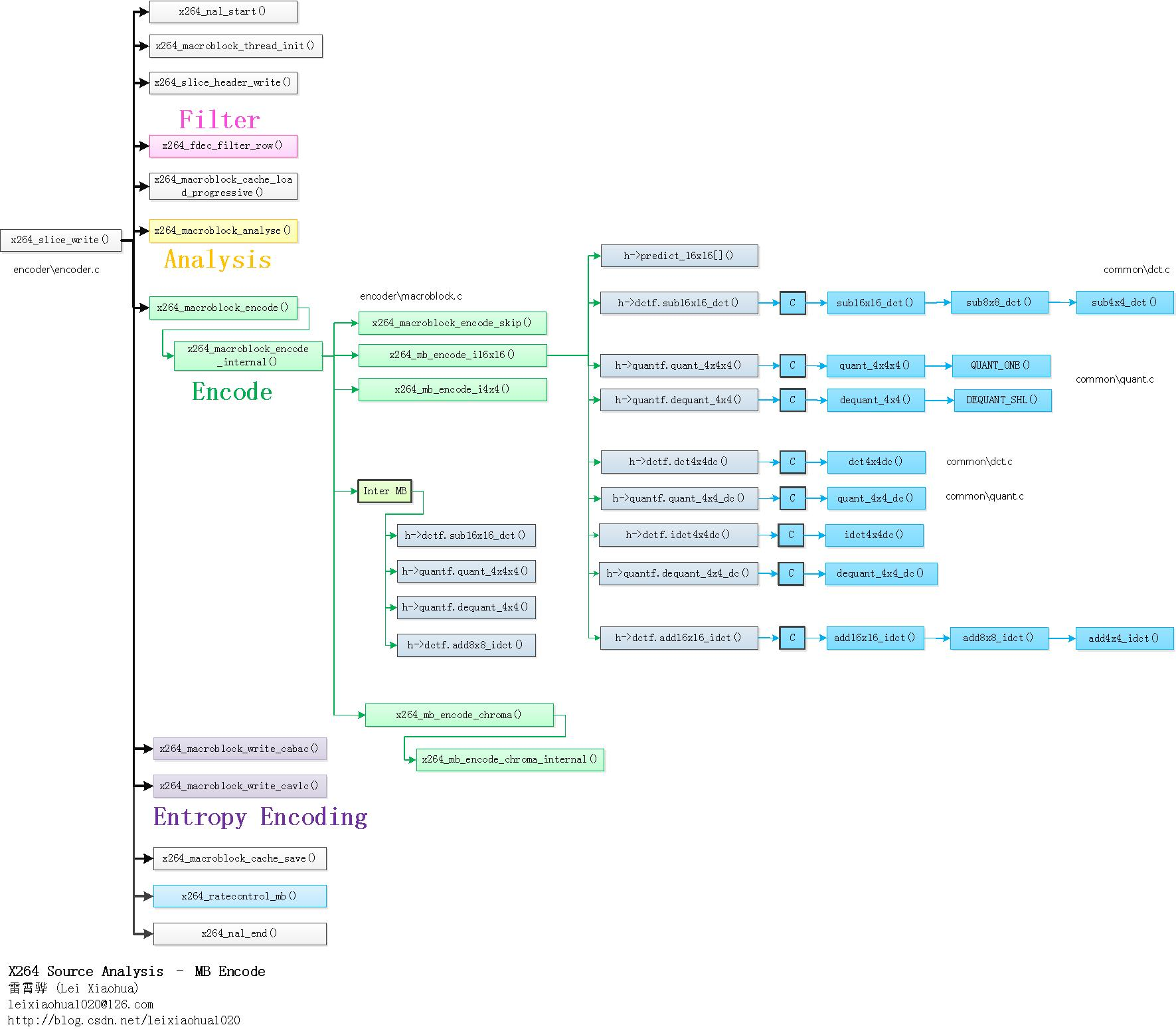
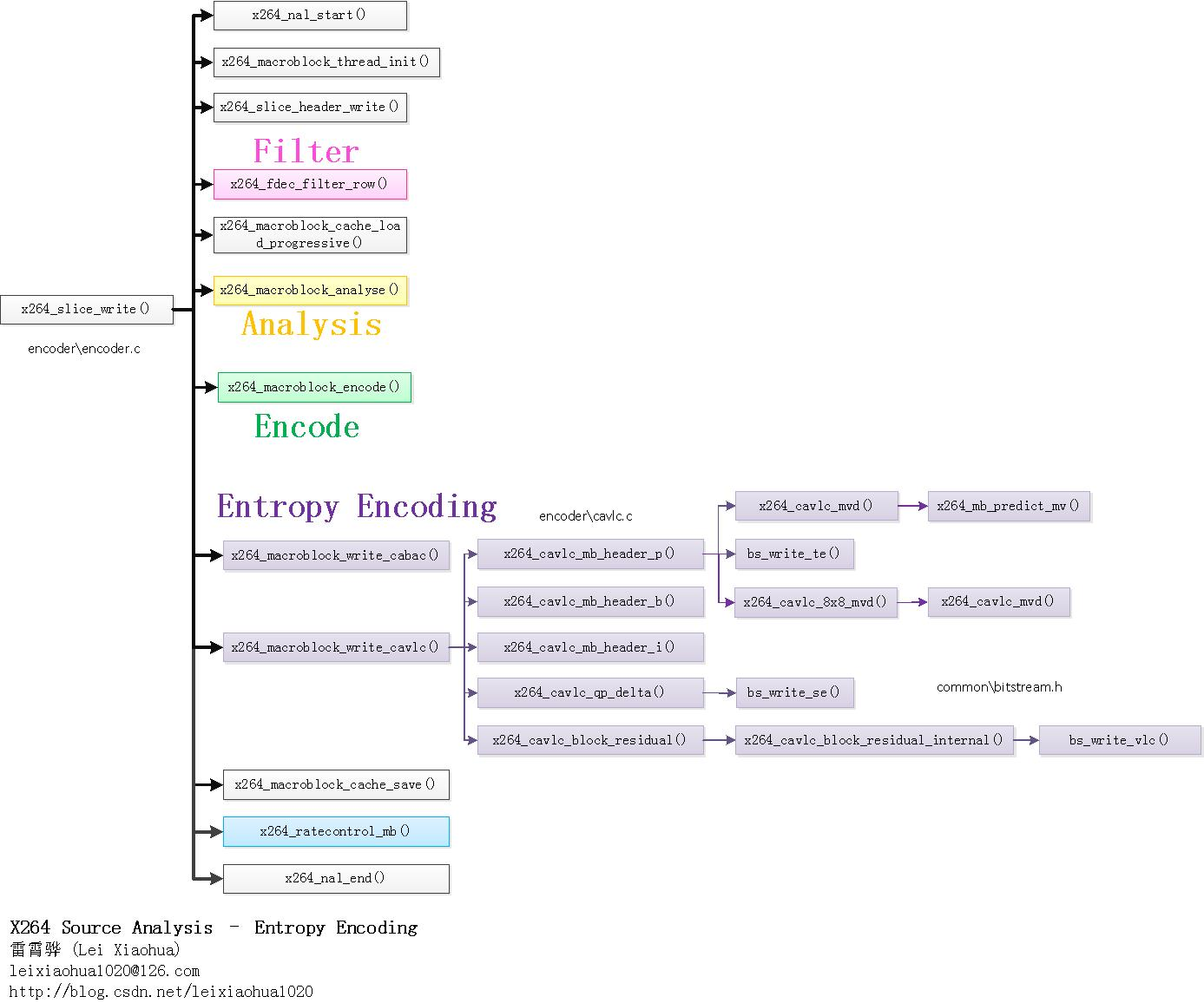
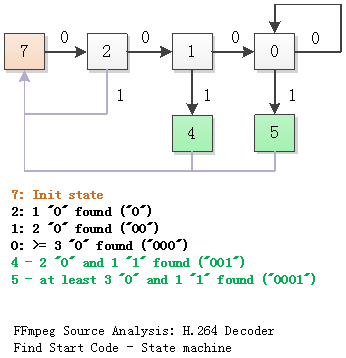
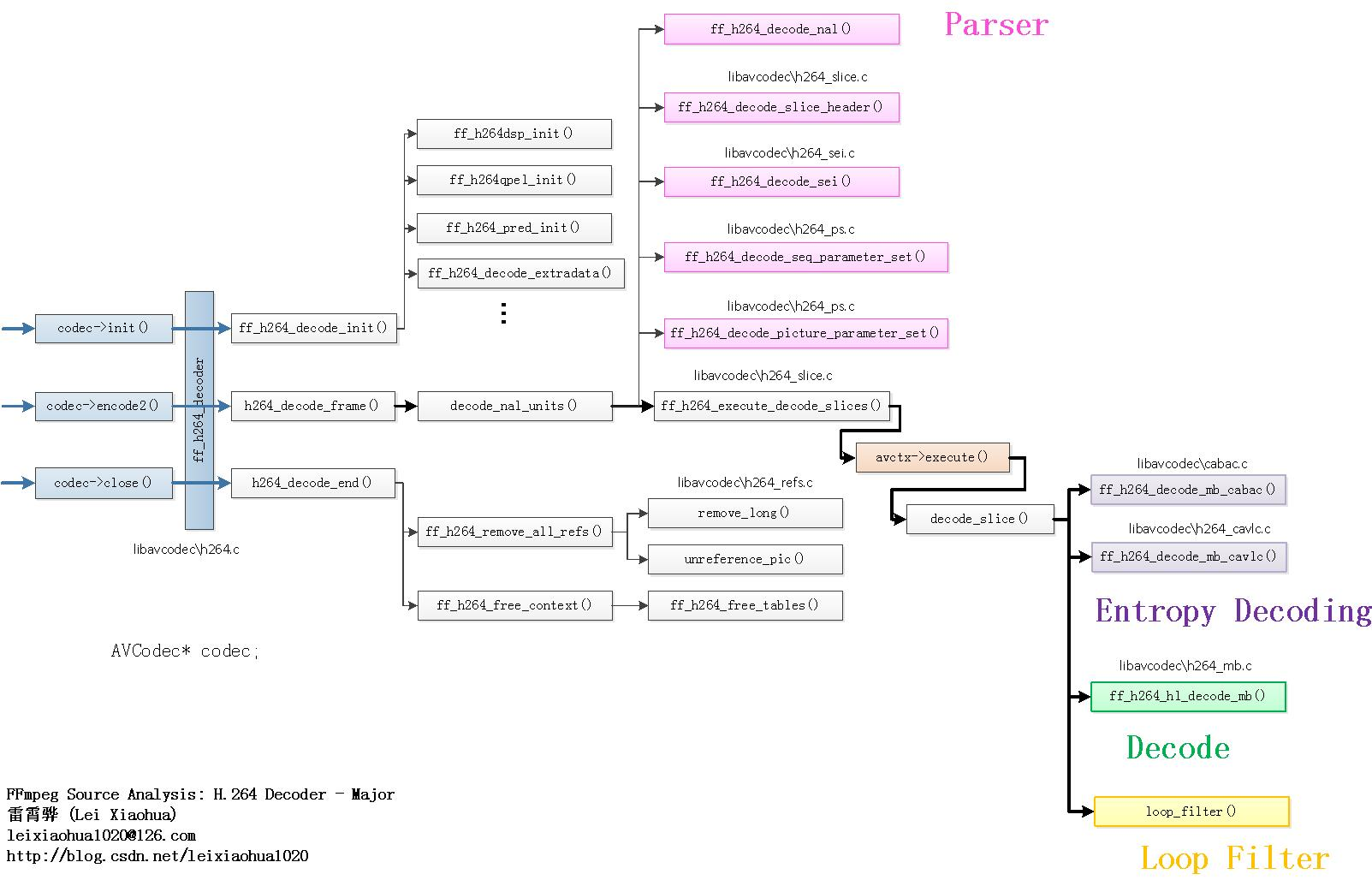
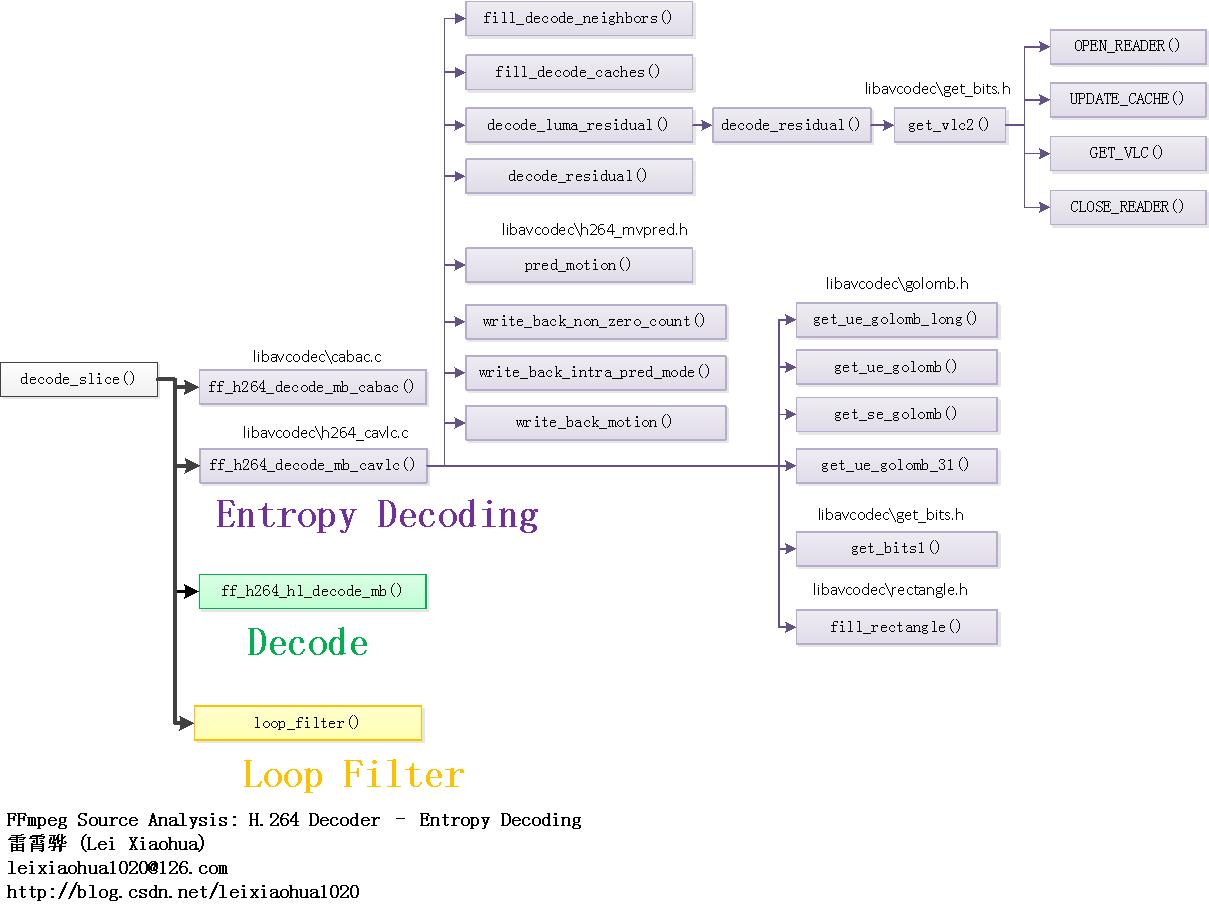
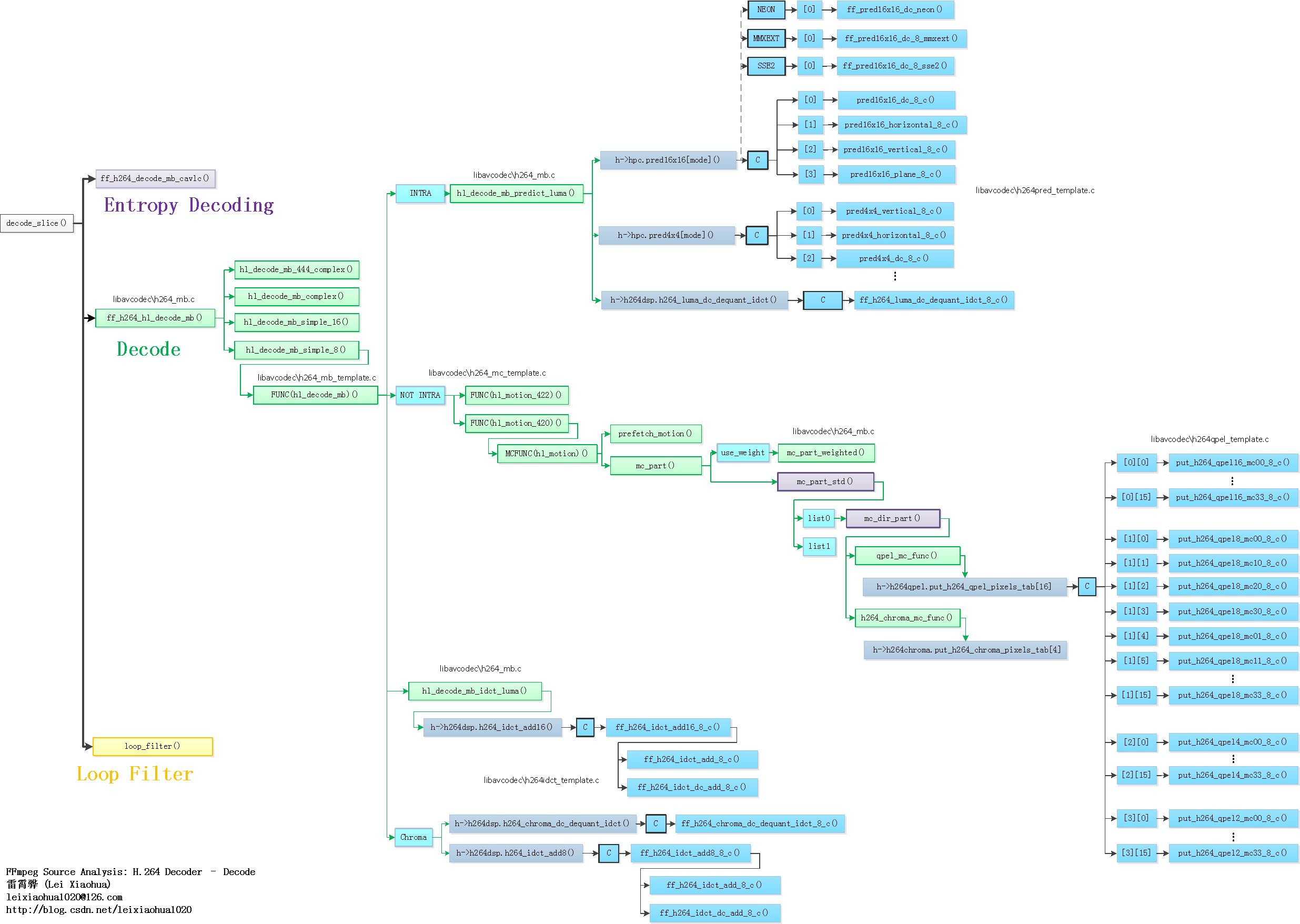




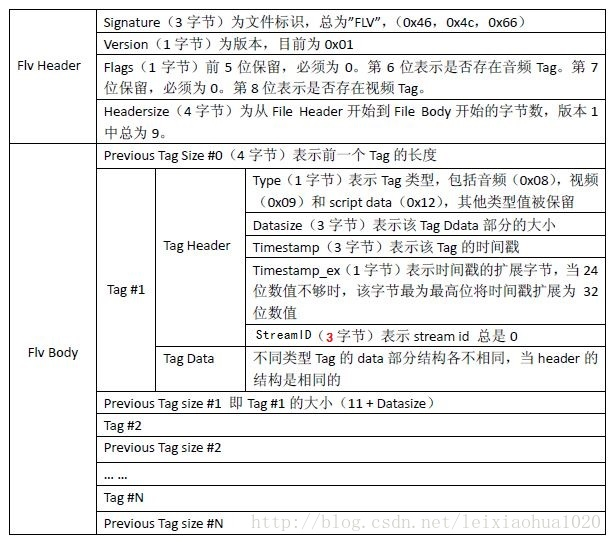



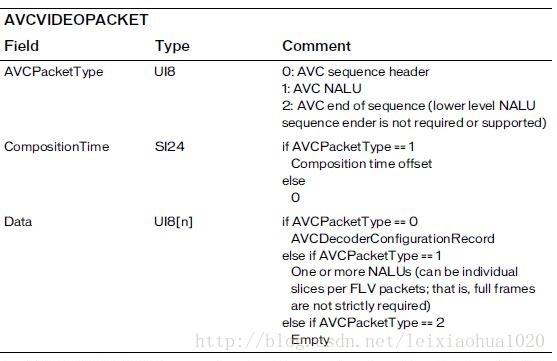
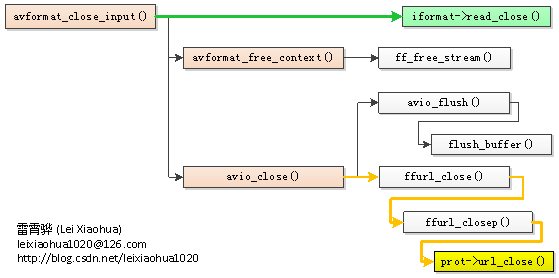
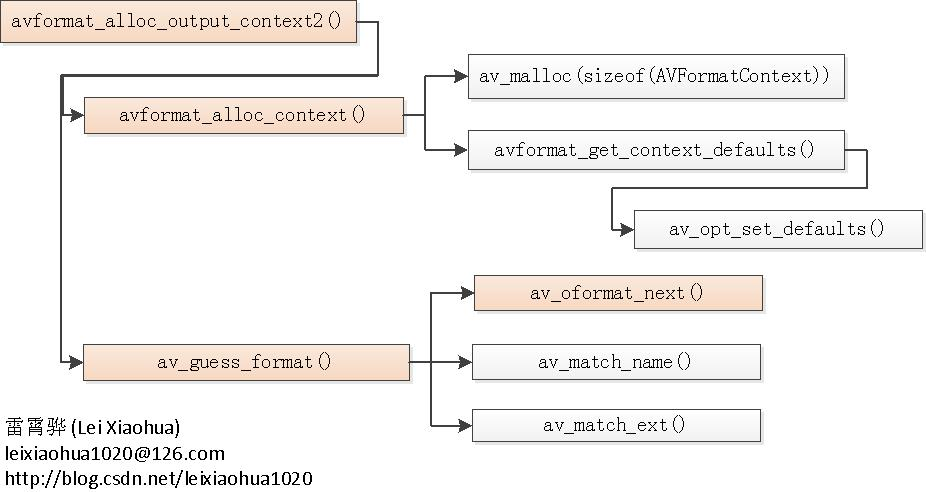


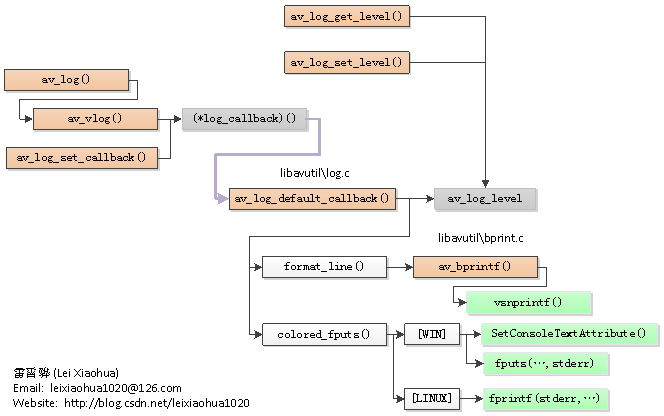

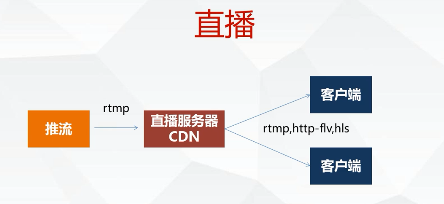
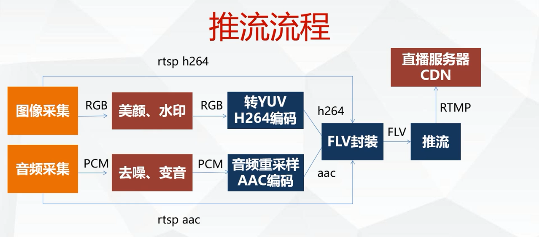

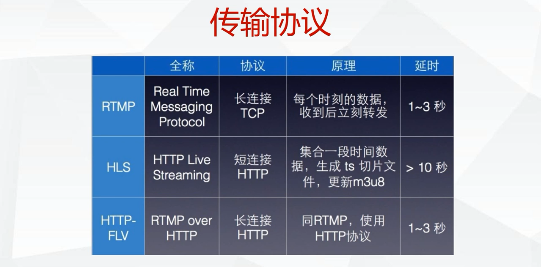






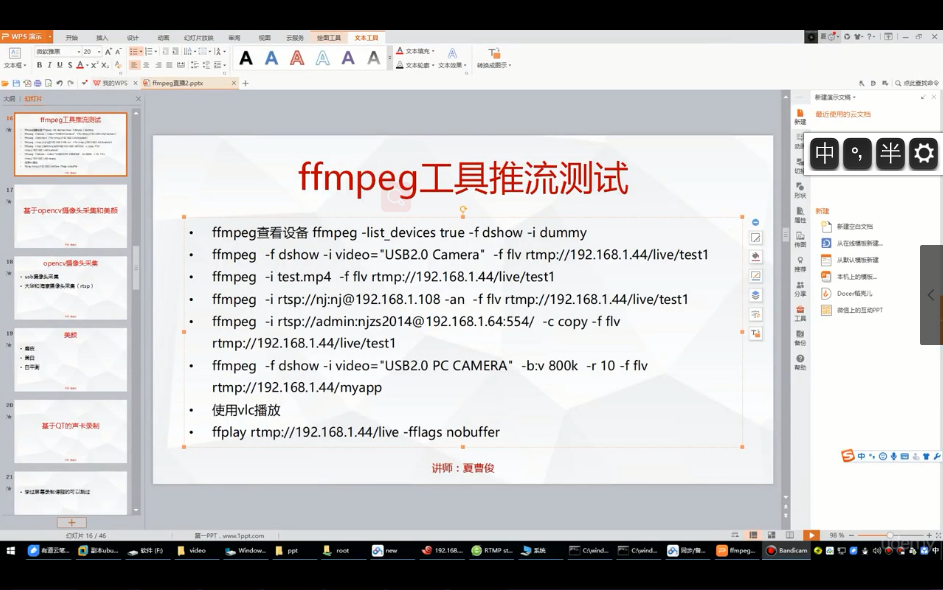




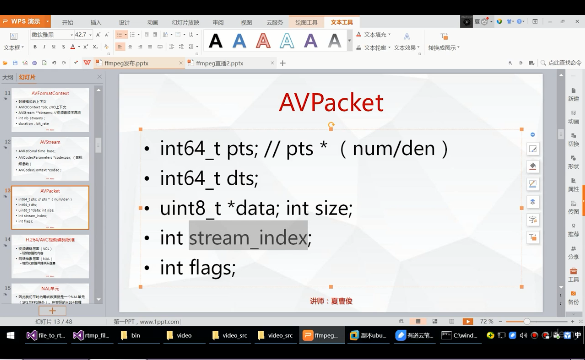
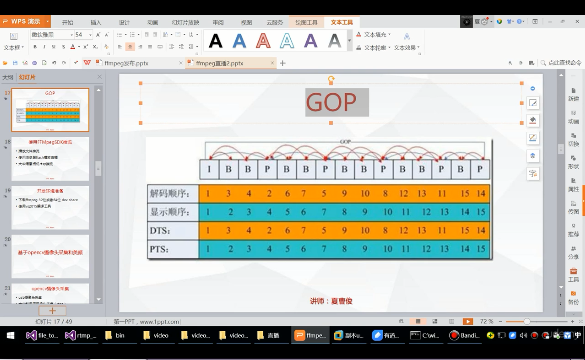





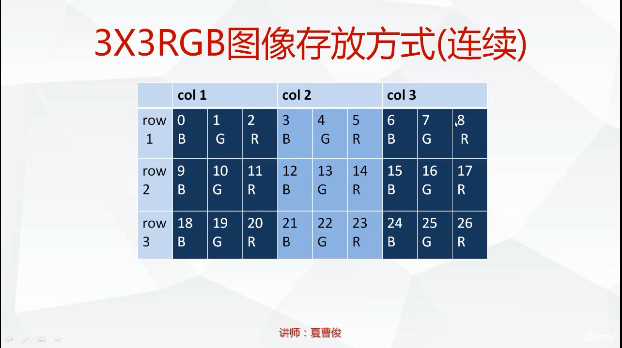






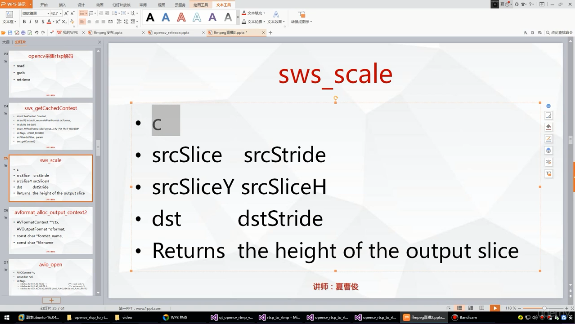







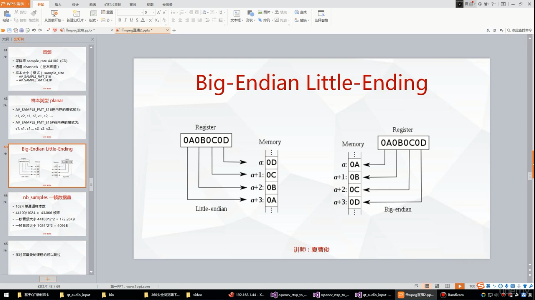
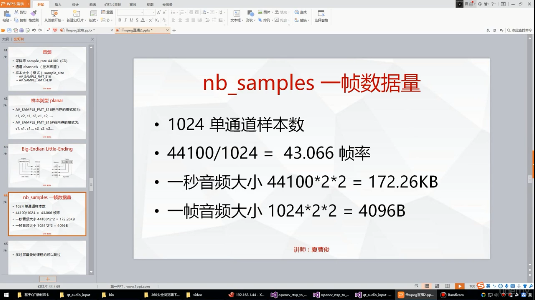









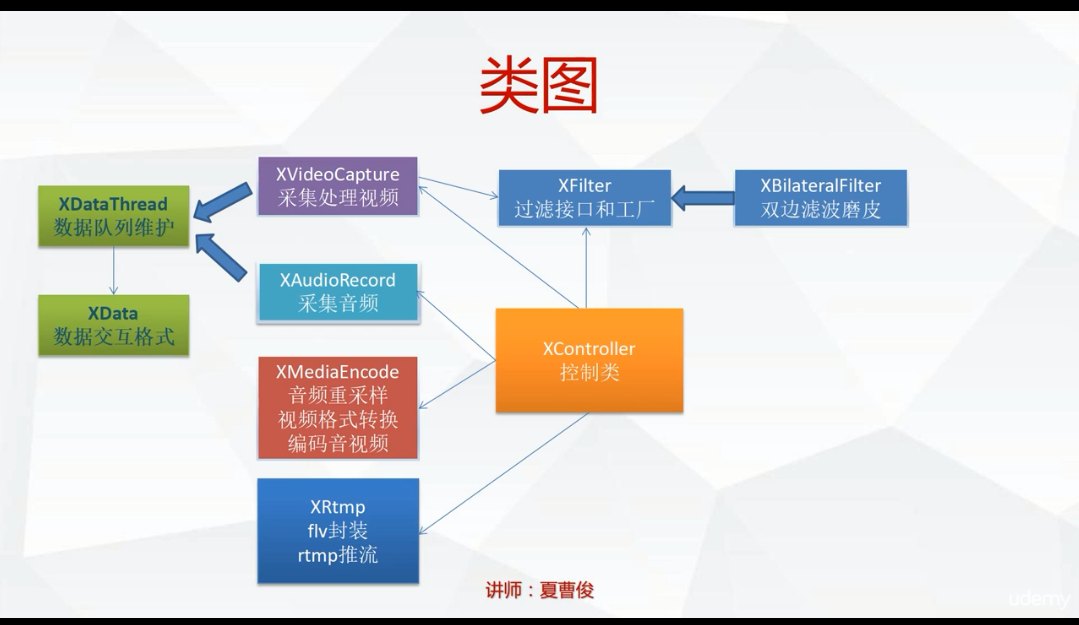













 ]]>
]]>

















 ]]>
]]>